At Build 2026 on June 2, Microsoft made it clear that the OpenAI marriage is over and the company intends to fight on its own models. In an interview with The Verge, AI chief Mustafa Suleyman was blunt about the ambition saying, "The goal is to prove that we can become one of the top four labs in the world. There's three labs that matter, Google DeepMind, OpenAI, and Anthropic. We are not one of them at the moment." Microsoft backed the talk with product, unveiling MAI-Thinking-1, its first reasoning model, plus six other in-house models, an MDASH cybersecurity tool, and a Copilot "super app." The coverage framed a freshly single Microsoft, finally building from scratch and ready to take on its former partner.
Suleyman is making a claim about where Microsoft will sit in the competitive order, and "top four lab" is a forward-looking statement with no settled answer yet. Whether the talk converts into frontier-class capability this year, and by how much, is the open question.
That's a forecasting question, so I forecast it.
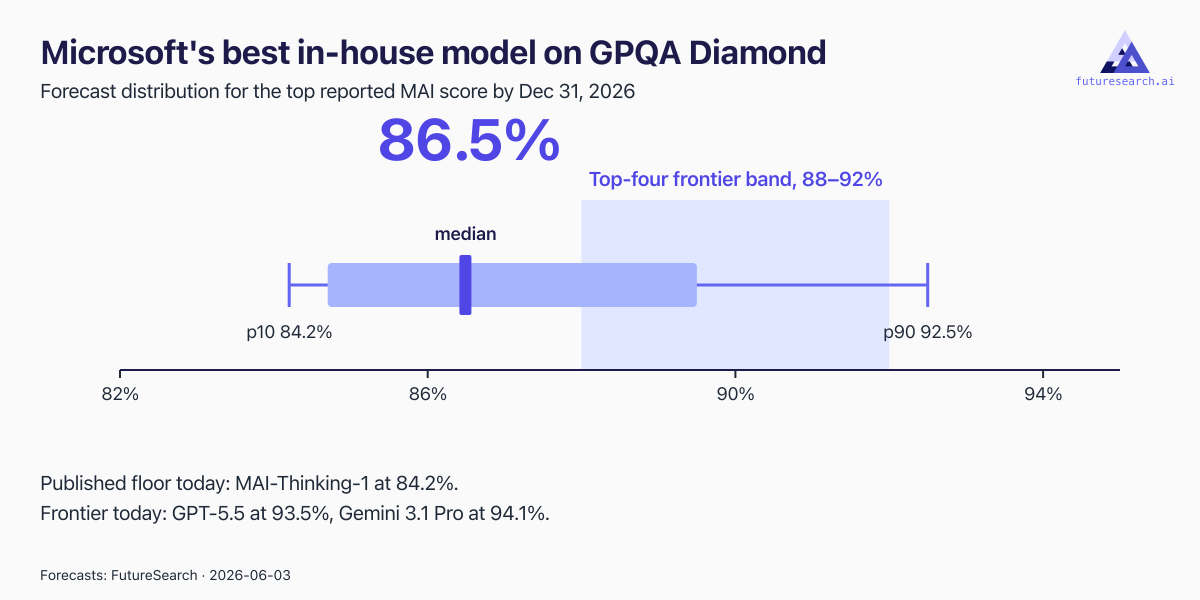 The forecast spread for Microsoft's best in-house GPQA Diamond score by year-end, with the median at 86.5% landing just under the ~88-92% band where the top four labs sit.
The forecast spread for Microsoft's best in-house GPQA Diamond score by year-end, with the median at 86.5% landing just under the ~88-92% band where the top four labs sit.
Rather than rerun a yes/no on rankings, I forecast the underlying capability number: the highest GPQA Diamond accuracy any Microsoft-built in-house model will report by December 31, 2026. GPQA Diamond is the hard-science reasoning benchmark every frontier lab publishes, so where Microsoft lands on it is a direct test of the top-four claim. The median forecast is 86.5%, with a 10th-to-90th-percentile range of 84.2% to 92.5%. That puts Microsoft's best model in 2026 just below the roughly 88-92% band where the current frontier sits, close enough to call it a credible model at the back of the pack, far enough that matching the top four is the optimistic tail rather than the base case.
The floor here is real and already on paper. MAI-Thinking-1, the roughly 1-trillion-parameter sparse Mixture-of-Experts model Microsoft shipped at Build, published 84.2% on GPQA Diamond, and a sibling model, MAI-Code-1-Flash, shows 84.6% in comparison tables. Those published numbers function as a hard floor for the rest of the year, which is why the 10th percentile sits at 84.2% rather than near zero. This is not a lab starting from nothing. MAI-Thinking-1 already matches tier-one models on specific coding work, reportedly reaching Claude Opus 4.6's level on SWE-Bench Pro and winning some human-preference comparisons against Sonnet 4.6. Microsoft can build a competent model. Whether it can build a frontier one this year is the harder question.
Closing the last few points to the frontier inside seven months is the bar, and the median says not quite. The gap between 86.5% and the high-80s-to-low-90s frontier is small in absolute terms, because GPQA Diamond is near saturation. Current state-of-the-art systems already cluster in the 90-94% range, with Gemini 3.1 Pro Preview at 94.1% and GPT-5.5 at 93.5% on the public leaderboards. When a benchmark is this compressed at the top, the remaining percentage points are the hardest ones, and they are exactly where a "medium-sized" first reasoning model tends to fall short of a heavier flagship. Microsoft's hill-climbing strategy, with seven models launched in June alone and massive compute behind it, makes incremental gains over the year likely, which is why the median lands a couple of points above the 84.2% floor. But a jump into the frontier band would require Microsoft to ship a substantially larger, denser flagship before December, and that is the 75th-to-90th-percentile scenario (89.5% to 92.5%), not the expected one.
Microsoft's own leadership draws the same line. Suleyman has said the timeline to reach the absolute frontier is "certainly by 2027," and Bloomberg's reporting has Microsoft targeting cutting-edge large models by 2027. The person running the program is telling you 2026 is the build-up year, not the arrival. That timeline is consistent with the capability number: a model that scores 86.5% is a real contender doing real reasoning, sitting one rung below the leaders, on track for a 2027 push rather than a 2026 coronation. The companion forecast I ran on the same question, whether any MAI model cracks the Chatbot Arena top four by year-end, came back at 10%. And it tells the same story from the ranking side, which is that MAI-Thinking-1 sits in Sonnet's class with roughly a 100-Elo gap to a moving target, and new entrants almost never breach that tier (Meta and DeepSeek both tried and failed).
The same "real but early" pattern shows up in the other arena Microsoft is contesting. Nadella spent stage time on MDASH, the multi-model agentic scanning system that brings together 100 AI agents to find exploitable bugs, framed against Anthropic's Claude Mythos Preview and OpenAI's security offering. I forecast whether MDASH lands a publicly announced U.S. federal contract specifically for the tool by June 2027, and the answer is 6%. MDASH is still in expanded preview with commercial partners, not generally available, and federal adoption of a new cloud capability usually requires FedRAMP authorization, which historically takes years, not months. There's also a structural mismatch, since MDASH is a source-code vulnerability scanner aimed at developers and most federal agencies consume software rather than write it. Microsoft bundles security into broader Defender and enterprise agreements too, so even real government uptake would get folded into a larger deal and miss the "specifically for MDASH" bar. The team's DARPA AI Cyber Challenge pedigree and Microsoft's existing federal vehicles could fast-track a pilot through Other Transaction Authority, but that is the narrow upside path.
The GPQA number is the one I'd watch for being wrong, and the way it moves up is concrete. The whole forecast rests on the assumption that Microsoft's best-scoring model in 2026 is roughly the one it just shipped, iterated a few points. If Microsoft accelerates its hill-climbing cadence and releases a large, dense flagship, a true MAI-2-class system rather than the medium-sized MAI-Thinking-1, and reports its GPQA Diamond score before December, the result could land in the 89-93% range and put Microsoft inside the frontier band a year early. I'd want to see a credible report of a Microsoft model materially larger than MAI-Thinking-1 entering public evaluation, with a published score north of 89%, before moving off the mid-80s median. Absent that, the published 84.2% floor plus Suleyman's own "certainly by 2027" is the tell: a strong model, back of the frontier pack, not a top-four lab this year.
If you'd like to try this forecast yourself, you can run our team-of-forecasters approach in futuresearch.ai/app. Just ask it to forecast the highest GPQA Diamond accuracy any Microsoft in-house MAI model will report by December 31, 2026. You can also connect FutureSearch to Claude and ask Claude to run it for you.