Your lead data is a mess. Some leads have company info but no title. Others have email but no company size. Traditional lead scoring breaks when data is incomplete because it can't score what it can't measure. This tutorial shows how to score 1,000 leads even with fragmented data, using AI that infers missing attributes and scores based on available information. Total cost: $13 for 1,000 leads.
My Problem: Drowning in leads
Suppose you run sales for a B2B SaaS company selling a data-integration platform. You have a long list of leads, like this 1000-business dataset sourced from ZoomInfo, that you want to qualify and prioritize.
Your ideal customer has serious data fragmentation issues due to operating across multiple locations or entities, across many point solutions. How can you tell which of your leads are like this?
Your CRM won't give you much insight into these characteristics. When I've done this, I find that simple heuristics don't work, because companies with different profile matches can look very similar.
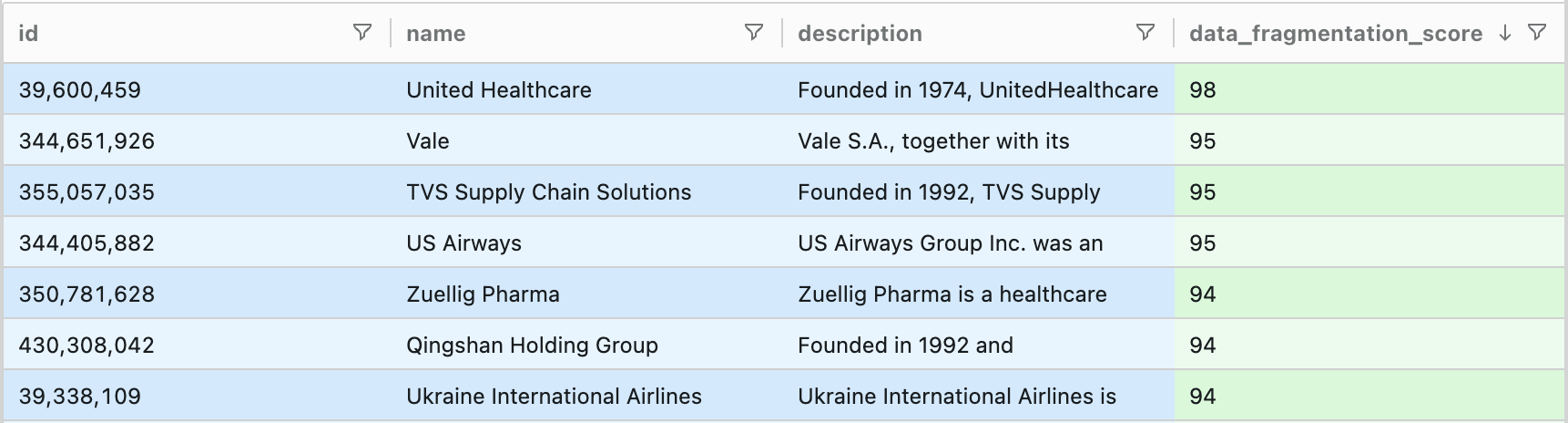
In our dataset, for example, Ultramain Systems and Ukraine International Airlines are both classified as "Airlines, Airports & Air Services" companies, and have similar revenues and employee counts. But Ultramain Systems sells software to airlines (operationally simple business, low fragmentation risk expected) while Ukraine International Airlines is an airline (operationally complex business, high fragmentation risk expected).
Enrichment tools like Clay and ZoomInfo add data fields, but they do not interpret them. They can tell you a company uses WordPress and Salesforce, but not whether that combination suggests data problems.
Manual review would take about 5 minutes per company, so 12/hour, so 1,000 is wildly beyond a reasonable amount of time.
Here's how I did it. I used futuresearch.ai/rank to reason about all 1,000 rows, and had AI agents search the web for some leads where necessary. It flexibly and efficiently ranked my leads, and it took 7 minutes and cost $13.
Here are some examples of leads EveryRow identified as good and bad, and why:
High-Ranking Examples
Company | Reasoning |
|---|---|
| Utah Food Bank 500 employees, $34M revenue | Coordinates 300 partner agencies across 29 counties, distributes 31 million meals, and tracks 10,000 donors. Each agency operates semi-autonomously with its own systems. |
| United Medical Center 80 employees, $16M revenue | Healthcare organizations typically struggle with data fragmentation due to EHR systems, patient billing, and regulatory compliance across disconnected platforms. |
| United Networks of America 102 employees, $29M revenue | Manages networks for 120 million members and 240,000 providers across dental, vision, and pharmacy. Each specialty network maintains separate data systems. |
Low-Ranking Examples
Company | Reasoning |
|---|---|
| Zip Software company, founded 2020 | Builds procurement software. As a modern SaaS company, their internal operations run on a unified stack without legacy fragmentation. |
| Zama Cryptography software, 78 employees | Develops encryption libraries. Their business model involves R&D rather than complex operational data workflows. |
So how good are the results?
I looked at the industries most represented in the top and bottom 50 leads. Among the top 50, I find the three most common industries to be Hospitals & Clinics, Banking, and Industrial Machinery & Equipment, all of which have structural factors that generate data fragmentation. Among the bottom 50, they're Software General, Business Intelligence (BI) Software, and Engineering Software.
Finally, I see that my Ultramain Systems versus Ukraine International Airlines example behaves as expected: Ukraine International Airlines ranks as the 7th most promising lead, while Ultramain Systems ranks about 50 from last.
At the end of the day, the only way to know if a ranking is good is whether the leads convert. We use EveryRow to rank our leads, and we're motivated to make it more accurate and cheaper.
Try it yourself
If you'd like to try this for yourself with the FutureSearch SDK, here's the code:
import os
from futuresearch import create_client, create_session
from futuresearch.ops import rank
import pandas as pd
os.environ["FUTURESEARCH_API_KEY"] = "your-api-key"
prompt = "Rank these companies according to the likely severity of their data-fragmentation issues and resulting need for a data-integration platform."
df = pd.read_csv("path/to/dataset.csv")
async with create_client() as client:
async with create_session(client=client, name="Data Fragmentation Leads") as session:
result = await rank(
session=session,
task=prompt,
input=df,
)
Simple!