
The newly released BTF-2 benchmark shows certain agents being better forecasters than others. What accounts for the difference? Here, I want to focus on what is sometimes called "unknown unknowns", or the ability of an agent to deal with its own uncertainty. This is pretty easy to identify in forecasting tasks, because it's impossible to have all the information to predict the future.
One thing we looked for to see how LLMs deal with their own uncertainty is explicit reasoning about why it might be wrong. The best forecasting agent we studied, before it commits to a number, tends to run a "pre-mortem", imagining the future unfolds differently and asking why. It considers how someone with different priors would read the same evidence. It looks for wildcards/black swans fairly often.
The frontier agents, Claude Opus 4.6, GPT-5.4, and Google Gemini 3.1 Pro, rarely explicitly reason in this way, and their performance is worse. (We don't know if this is causal.) The full analysis is in our recent paper Evaluating Strategic Reasoning in Forecasting Agents.
We used Tetlock's CHAMPS KNOW framework (Tetlock and Gardner, 2015), a set of 10 dimensions developed in the Good Judgment Project that capture how the best human forecasters think. A Gemini 3.1 Pro agent ranked each dimension's prominence in every forecast rationale, across 1,367 questions. The resulting Table 7 show how the three dimensions related to "unknown unknowns" are the main difference between the best forecaster and the rest.
This gives a pretty clear signal of room for improvement even in frontier LLMs that are getting to be very good general purpose reasoners. LLMs, like humans, could do better with self-awareness of uncertainties.
Unknown unknowns
Three of the ten CHAMPS KNOW dimensions are about epistemic self-awareness. Some more detail:
-
Pre/Post-mortem: the agent enumerates ways its own forecast could be wrong. For example, on the question of whether Congress would enact a federal CR with an expiration after November 21, the SOTA rationale (forecast 84%, resolved YES) included an explicit "Strongest Arguments for No" list naming three concrete pathways to its own failure, the first being "A historic, multi-month shutdown: ... If no compromise is reached, the shutdown could theoretically persist continuously through December 31, meaning no CR is enacted at all." Top-3 frequency: SOTA 37.8%, Opus 4.6 9.5%, GPT-5.4 6.8%, Gemini 3.1 Pro 4.3%.
-
Other Perspectives: showing how different priors would read the same evidence. The SOTA forecaster does this structurally, with the "Strongest Arguments for Yes" and "Strongest Arguments for No" sections in the rationales, which you can see for yourself in BTF-2 HuggingFace dataset. Top-3 frequency: SOTA 20.3%, Opus 5.1%, GPT-5.4 1.6%, Gemini 1.7%.
-
Wildcards: events outside any trend line. From the same CR question: "The administration's willingness to tolerate a prolonged shutdown to reshape the federal bureaucracy is a major wildcard." From a question on the WTA year-end #1 ranking: "the highly improbable scenario where Świątek suddenly reverses her break, takes a last-minute wildcard into a remaining WTA 250 or 500 event, wins it, and goes undefeated at the WTA Finals, while Sabalenka fails to win a single match." Top-3 frequency: SOTA 2.9%, Opus 0.7%, GPT-5.4 0.3%, Gemini 0.7%.
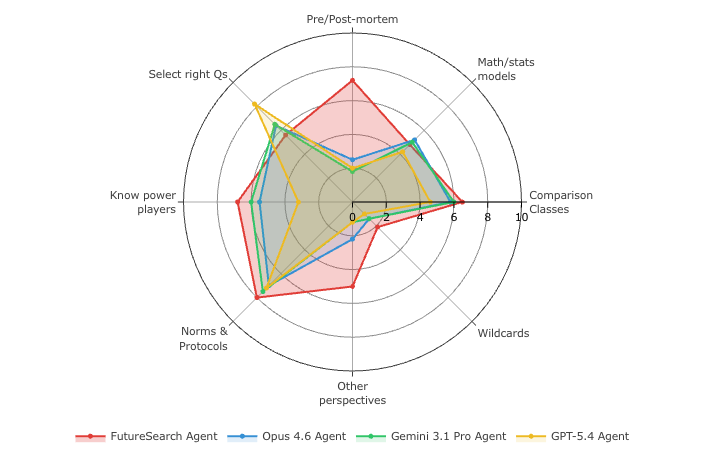
Again, we can't say causally yet that weaknesses in these dimensions lead to worse forecasts, but the correlation is striking because the gap is so large between the better forecaster. Summing all three, the SOTA forecaster's rationales focus on these 61% of the time. The Claude Opus 4.6 agent is at 15%, the GPT-5.4 agent at 9%, and the Gemini 3.1 Pro agent at 7%.
Forecasting tasks may be a good way to train LLMs to reasoning about uncertainty. Or it might get better at this in some emergent way. I think that's what we've been seeing so far, Opus 4.6 is better at self-awareness of blind spots than Opus 3.5 presumably just by being a better model overall.