You have a contact list with duplicates, but they have different email addresses, different phone numbers, or incomplete data. Traditional deduplication requires an exact match on email or phone, but what if your duplicates are "John Smith, Acme Corp" and "J. Smith, Acme Inc"? This tutorial shows how to identify duplicate contacts using fuzzy name matching and company association, even when standard identifiers don't match. We deduplicated 200 research contacts for $0.39.
The User's Problem
This case study is inspired by a common Salesforce pain point: companies purchase AI tools like Agentforce but can't use them because their CRM data is a mess—same contacts listed 3-4 different ways, missing emails, and records linked to wrong accounts.
"We bought Agentforce licenses but they're just sitting there. Same companies listed 3-4 different ways, contacts missing emails, opportunities linked to wrong accounts. We need clean data before any AI can actually work." — r/salesforce user
I faced a similar problem building a database of AI researchers from academic lab websites. Scraping produced:
- Name variations: "Julie Kallini" vs "J. Kallini", "Vincenzo Moscato" vs "Moscato, Vincenzo"
- Typos: "Hanshen Chen" vs "Hansheng Chen", "Bryan Wiledr" vs "Bryan Wilder"
- Career changes: Same person listed at "BAIR Lab" and later at "BAIR Lab (Former)" with different emails
- GitHub handles: Sometimes the only reliable link between records like "Alexandra Butoi" and "A. Butoi" sharing
butoialexandra - Nicknames: Research shows some people go by shortened names (Robert/Bob, William/Bill)
The Dataset
We used a synthetic dataset designed to mirror real CRM deduplication challenges. The schema includes name, position, organization, email, university, and GitHub—with realistic data quality issues:
row_id | name | position | organization | university | github | |
|---|---|---|---|---|---|---|
| 2 | A. Butoi | PhD Student | Rycolab | ETH Zurich | butoialexandra | |
| 8 | Alexandra Butoi | — | Ryoclab | — | — | butoialexandra |
| 43 | Namoi Saphra | Research Fellow | — | nsaphra@alumni | - | nsaphra |
| 47 | Naomi Saphra | — | Harvard University | — | nsaphra | |
| 18 | T. Gupta | PhD Student | AUTON Lab (Former) | — | Carnegie Mellon | tejus-gupta |
| 26 | Tejus Gupta | PhD Student | AUTON Lab | Carnegie Mellon | tejus-gupta |
The dataset contains 200 rows representing 160 unique people, with duplicates ranging from easy (exact GitHub match) to expert-level (minimal distinguishing information, adversarial pairs).
Alternative Approaches
Approach | Limitation |
|---|---|
Fuzzy string matching fuzzywuzzy, rapidfuzz | Threshold problem: too low catches false positives, too high misses "A. Butoi" ↔ "Alexandra Butoi" which has low character overlap |
Email/ID matching | Fails when same person has different emails at different institutions |
Power Query Fuzzy Lookup | Single-column only, struggles with row alignment after merge, users report giving up |
Rule-based systems | Requires maintaining hundreds of edge cases for name variations, nicknames, abbreviations |
Enterprise MDM Cloudingo, DataGroomr | $1,000-2,500/year, requires deployment and oversight—overkill for one-off cleanups |
Manual review | 200 rows × ~5 comparisons each = hours of tedious work |
The core issue: deduplication requires semantic understanding. Is "Robert" the same as "Bob"? Is "BAIR Lab (Former)" the same organization as "BAIR Lab"? These are judgment calls that need context.
How FutureSearch Dedupe Works
The deduplication pipeline has five stages:
-
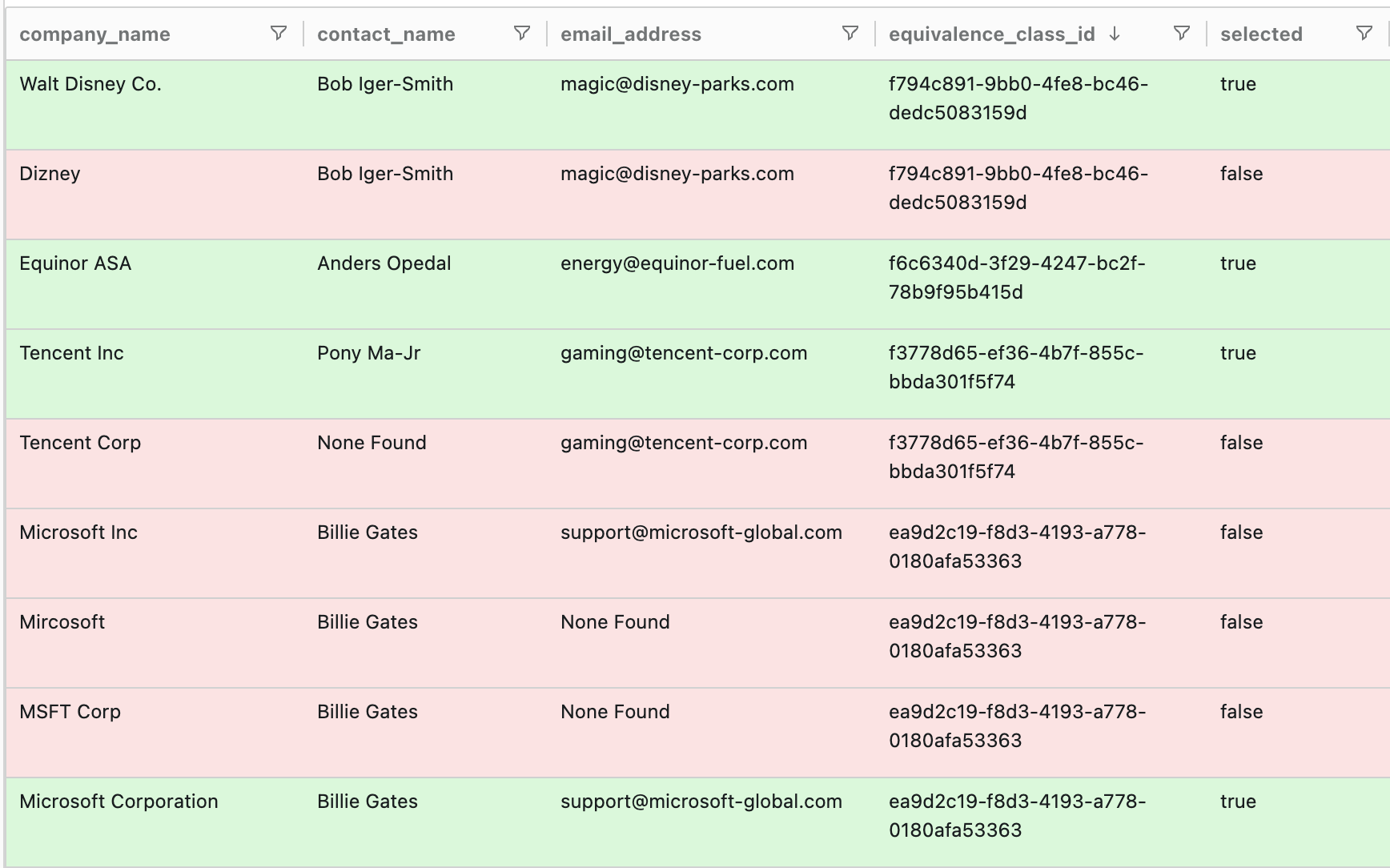
Semantic Item Comparison: Each row is compared against others using an LLM that understands context—recognizing that "A. Butoi" and "Alexandra Butoi" are likely the same person, or that "BAIR Lab (Former)" indicates a career transition rather than a different organization.
-
Association Matrix Construction: Pairwise comparison results are assembled into a matrix of match/no-match decisions. To scale efficiently, items are first clustered by embedding similarity, so only semantically similar items are compared.
-
Equivalence Class Creation: Connected components in the association graph form equivalence classes. If A matches B and B matches C, then A, B, and C form a single cluster representing one entity.
-
Validation: Each multi-member cluster is re-evaluated to catch false positives—cases where the initial comparison was too aggressive.
-
Candidate Selection: For each equivalence class, the most complete/canonical record is selected as the representative (e.g., preferring "Alexandra Butoi" over "A. Butoi").
The Solution: 20 Lines of Code
from futuresearch import create_client, create_session
from futuresearch.ops import dedupe
import pandas as pd
input_df = pd.read_csv("researchers.csv")
async with create_client() as client:
async with create_session(client, name="Researcher Dedupe") as session:
result = await dedupe(
session=session,
input=input_df,
equivalence_relation=(
"Two rows are duplicates if they represent the same person "
"despite different email/organization (career changes). "
"Consider name variations like typos, nicknames (Robert/Bob), "
"and format differences (John Smith/J. Smith)."
),
)
result.data.to_csv("deduplicated.csv", index=False)
The equivalence_relation parameter tells the AI what counts as a duplicate. Unlike regex or fuzzy matching, this is natural language that captures the semantic intent.
Results
Metric | Value |
|---|---|
| Input rows | 200 |
| Output rows (unique) | 156 |
| Expected unique | 160 |
| Duplicates found | 44 |
| Expected duplicates | 40 |
| Cluster accuracy | 156/160 (97.5%) |
| Row accuracy | 98% |
| Processing time | 90 seconds |
| Total cost | $0.39 |
Accuracy by difficulty:
- Easy: 100% (12/12)
- Medium: 93% (13/14)
- Hard: 100% (10/10)
- Expert: 50% (2/4 — these are adversarial cases with minimal distinguishing info)
- Distractor: 95% (19/20 same-first-name pairs correctly identified as different people)
- Singletons: 100% (100/100)
Comparison Table
What About Fuzzy String Matching?
A common first approach is fuzzy string matching using libraries like rapidfuzz or fuzzywuzzy. This method compares all row pairs using token-sorted string similarity and groups rows exceeding a threshold using Union-Find clustering. We benchmarked this approach at two thresholds:
| Metric | Fuzzy (t=0.75) | Fuzzy (t=0.90) | FutureSearch |
|---|---|---|---|
| Row accuracy | 86% | 82% | 98% |
| Cluster accuracy | 82% | 78% | 98% |
| Easy duplicates | 58% (7/12) | 17% (2/12) | 100% (12/12) |
| Hard duplicates | 70% (7/10) | 10% (1/10) | 100% (10/10) |
| Distractor accuracy | 90% (18/20) | 100% (20/20) | 95% (19/20) |
| Processing time | 0.04s | 0.04s | 90s |
| Cost | $0 | $0 | $0.39 |
Fuzzy matching is ~2000x faster and free, but has a 12-16% accuracy gap. At aggressive thresholds (0.75), it catches more duplicates but risks false merges. At conservative thresholds (0.90), it avoids false merges but misses most semantic duplicates like "T. Gupta" ↔ "Tejus Gupta".
Qualitative Comparison
| Capability | Fuzzy Matching | Manual Review | FutureSearch |
|---|---|---|---|
| Handles nicknames (T. ↔ Tejus) | ✗ | ✓ | ✓ |
| Handles career changes | ✗ | ✓ | ✓ |
| Avoids false merges (distractors) | ✓ (at high threshold) | ✓ | ✓ |
| Scales to 10K rows | ✓ | ✗ | ✓ |
What About ChatGPT?
A natural question: why not just upload the CSV to ChatGPT and ask it to deduplicate?
We tested this with the prompt:
Deduplicate this dataset. Remove duplicate rows, keeping one representative
row per unique entity. Equivalence rule: Same person = same individual.
Select the best representative from each equivalence class you identify.
Result: 56% row accuracy (vs FutureSearch's 98%)
| Metric | ChatGPT | FutureSearch |
|---|---|---|
| Row accuracy | 56% | 98% |
| Output rows | 72 | 156 |
| Expected unique | 160 | 160 |
| Data loss (over-merged) | 88 people deleted | 4 people deleted |
The problem: ChatGPT over-merged aggressively, "hallucinating" duplicates that don't exist:
- 88 unique people were incorrectly deleted (merged into other records)
- Only 33% of singletons preserved — people with no duplicates were merged into unrelated records
- Only 25% distractor accuracy — people with the same first name but different identities (like "Rohan Saha" and "Rohan Chandra") were incorrectly merged
This is the opposite failure mode from traditional deduplication. Rather than missing duplicates (under-merging), ChatGPT created false matches (over-merging), resulting in permanent data loss.
Example Matches
Correctly Identified Duplicates:
butoialexandrabutoialexandransaphransaphratejus-guptatejus-guptaCorrectly Identified as Different People:
simpleParadoxrohanchandra30Lost clusters (4 people over-merged):
smirchanisobrrjKey Takeaways
- 98% row-level accuracy on a challenging dataset with conflicting signals (same person, different email/organization due to career changes)
- $0.39 total cost and 90 seconds to process 200 records with AI-powered semantic matching
- 20 lines of code using the FutureSearch SDK
- Correctly handled name variations like "A. Butoi" ↔ "Alexandra Butoi", typos like "Namoi" ↔ "Naomi", and abbreviations like "T. Gupta" ↔ "Tejus Gupta"
- 95% accuracy on "distractor" pairs (people with same first name but different identities)
When to Use FutureSearch Dedupe
This approach works best when:
- Semantic judgment required: Name variations, abbreviations, nicknames
- Conflicting signals: Same person with different emails/organizations over time
- No single reliable key: Can't rely on email or ID alone
- Moderate scale: 100-10,000 rows where manual review is painful but not impossible
Try It Yourself
Run your own dedupe:
- Go to futuresearch.ai/app and sign in, or add FutureSearch to Claude
- Upload your dataset
- Write your equivalence relation in plain English
- View results in the web interface with full audit trail