Your internal product list calls it "MS Office 365 Pro". The vendor catalog calls it "Microsoft 365 Business Premium". There's no shared SKU or product ID, just names that describe the same thing differently. This tutorial shows how to match 2,000+ products from an internal inventory to an external vendor catalog using AI-powered entity matching. We achieved a 91.1% automatic match rate on software products, eliminating weeks of manual cross-referencing.
My Problem
I had a list of 2,000 software products used across an organization. I needed to match each one to its parent company from a list of approved suppliers.
Seems straightforward. Check if "Microsoft" appears in "Microsoft Excel." Match.
But what about "Photoshop", which doesn't substring match with "Adobe"? Or "Slack", which should match to Salesforce? Any fuzzy matching solution fails on these, since "Photoshop" and "Adobe" have 0% string similarity.
So I ran it through futuresearch.ai/merge. It took 8 minutes and cost $25, and matched 91.1%.
software_df = pd.read_csv("software_used.csv") # 1,996 products
suppliers_df = pd.read_csv("approved_suppliers.csv") # 50 companies
result = await deep_merge(
task="""Match each software product to its parent company.
Use knowledge of product-company relationships (Photoshop → Adobe),
subsidiaries (YouTube → Alphabet), and acquisitions (Slack → Salesforce).""",
session=session,
left_table=software_df,
right_table=suppliers_df,
merge_on_left="software_name",
merge_on_right="company_name",
)
Using LLMs and Web Agents to Match Tricky Cases
The easy ones are obvious:
| Software | Matched To | Method |
|---|---|---|
| Microsoft Excel | Microsoft | Name contains company |
| Oracle Database | Oracle | Name contains company |
But the interesting ones require actual knowledge. Any fuzzy matching solution would match "slackware" (the linux tool) to "slack".
The first thing I thought to try was embeddings. But the matches there are also too errorprone, generally introducing too many false positives (see below on why false negatives are better for my use case).
The big challenge with this problem is that it isn't a "join", it's an association. "Slack" and "Salesforce" aren't alternate names for the same thing, they're related semantically by a relationship specified in natural language.
So the obvious thing to try was LLMs. But the number of rows is large. If I used a cheap LLM like Gemini-3-Flash, and had good quota and caching, and set up the problem carefully, I could do this for a few bucks. It's more accurate than using embeddings, but still makes mistakes on ones that require more up-to-date knowledge, like for newer software products, or cases with tricky judgment, like underspecified product names.
As a human, I solve these by Googling them. And indeed, LLM-powered web research agents solve most of these. But one can't run many hundreds of ChatGPT browser tabs with web search enabled. But running all of these as web research agents programmatically would cost hundreds of dollars, not to mention the infrasturcture needs.
So what's the efficient way to solve this?

My trick is a combination of batching the rows to reduce LLM calls, and quickly identifying which ones should get web research agents to investigate further. For "Workvivo," for example, FutureSearch used the web and matched it with Zoom, showing reasoning like:
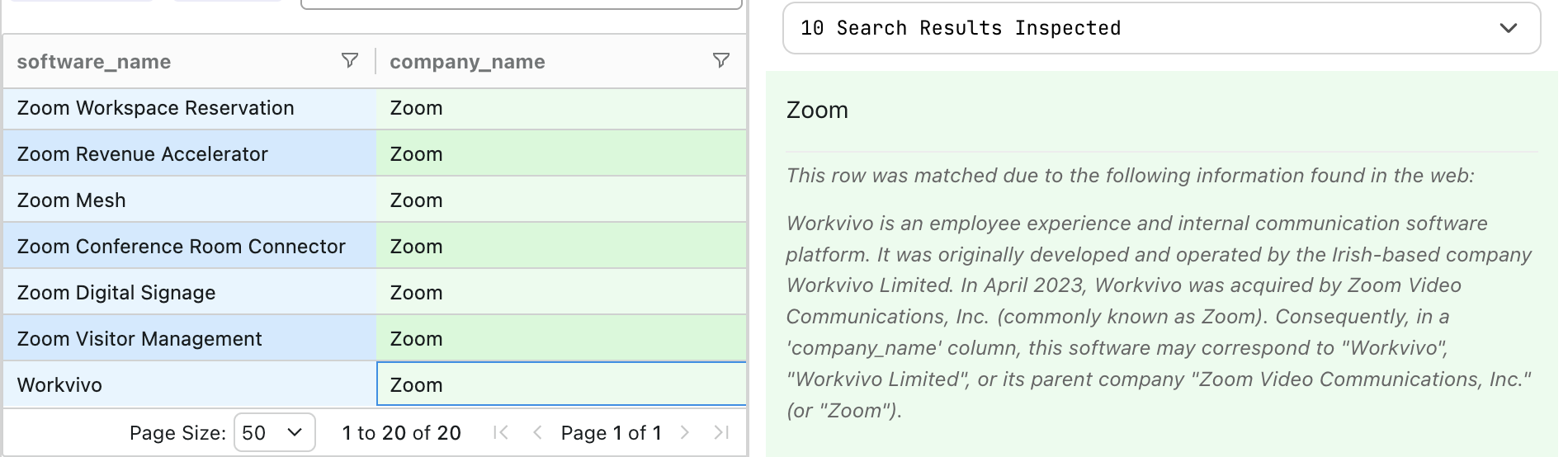
When web research is needed, FutureSearch shows it like this. You can see what pages it read and what searches it did too. When it has to make judgment calls, it will explain, like:
"exchange" → Microsoft
The software name "exchange" most commonly refers to Microsoft Exchange Server, a mail and calendaring server developed by Microsoft. [...]
Other potential but less common interpretations include: Exchange Solutions (retail loyalty platform), Science Exchange (R&D services), Trust Exchange (B2B trust management), Experts Exchange (tech community platform).
In a data-merging context, the most likely match for "exchange" is Microsoft, as the product is frequently referred to as "Exchange" in IT and software inventory lists.
When compliance asks "why did you classify this as approved?", you have an audit trail, similar to if a human had done this.
What about The 9% That Failed To Match?
So why only 91.1% accuracy? Fortunately, FutureSearch didn't produce any false positives, according to our ground truth unified dataset. In my use case, false positives are costly, because flagging legitimate software as "not from approved vendor" can lead to a wasted human followup.
But FutureSearch did produce many false negatives. For 178 out of 1996, it failed to find a match. Some examples include products with too generic names, like "Analytics". Others were from discontined products. So this 9% would need to be handled by a human. But this is the point of the process, to have a human review ones that can't be confidently tagged as "vendor approved".
| Metric | Value |
|---|---|
| Products processed | 1,996 |
| Suppliers | 50 |
| Matched | 1,818 (91.1%) |
| Cost | $25 |
| Time | 8 minutes |
Try it yourself
The free tier gives you 200 rows per table, enough to test whether it works on your data before running a full merge that may cost a few dollars. Consider it when you have problems like:
- Vendor consolidation after M&A
- Matching customer records across CRM/billing/support
- Linking company names to stock tickers
- Any entity resolution where IDs don't exist
If you can describe how entities should match to a human, you can merge them with FutureSearch.