Paper | Benchmarks Leaderboard
Predicting the future is a robust measures of general intelligence. But evaluating AI forecasters requires good questions and accurate resolutions, and a lot of them, because forecasting is probabilistic. It takes 1000+ hard questions about real-world developments to statistically distinguish a good forecaster from a great forecaster.
Even professionally curated platforms like Metaculus see roughly 8% of their questions annulled due to ambiguity or other issues. Not to mention the endemic resolution drama episodes around Polymarket and Kalshi markets (Maduro anyone?).
But if high quality forecasting questions can be generated at scale, they could serve as the ultimate benchmark of AI reasoning and research. It is impossible to saturate, and evaluates intelligence in a fully general way.
So we built a system that generates and resolves high-quality forecasting questions automatically and at scale, using LLM-powered web research agents. In the linked paper paper, we used it to produce and resolve 1,499 hard questions about news, business, and technology from Oct - Dec 2025, and resolved them. And we can make more.
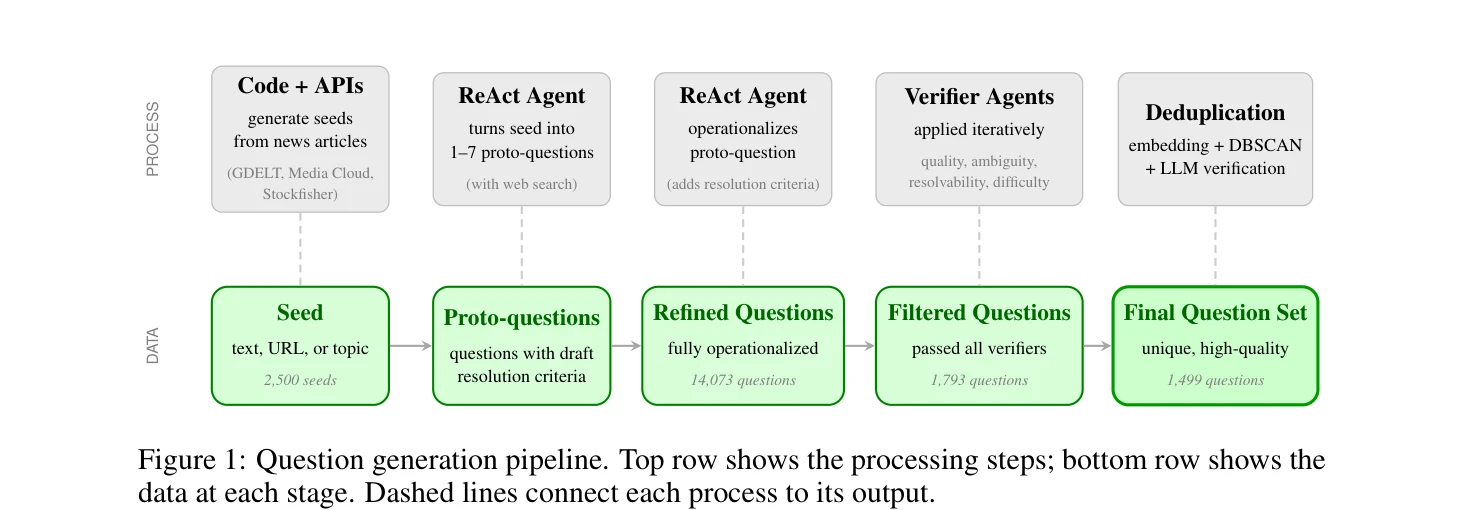
The Pipeline
Our question generation system starts with 2,500 seeds drawn from news articles (GDELT, Media Cloud) and revenue forecast rationales from Stockfisher for S&P 500 companies. A ReAct agent with web search proposes 1 to 7 proto-questions per seed, and another agent refines each into a fully operationalized forecasting question with precise resolution criteria. A series of verifier agents then assess quality, ambiguity, resolvability, and difficulty, and a final deduplication step using embeddings and DBSCAN removes near-duplicates. Of the 14,073 candidate questions generated, 1,499 survived this filtering.
The beauty is that, while it is expensive to run so many web research agents per question, it's far cheaper to generate these hard forecasting questions than it is to forecast them at expert level. Forecasting questions are cleanly objectively scoreable if you wait long enough, so this method can produce a nearly endless frontier of AI benchmarks that can never be saturated.
It turns out that verifying question quality is much easier than generating quality from scratch. By generating a large set, and aggressively filtering them, we produces questions that are unambiguous, consequential, and cover geopolitics, economics, law, and technology.
Results
We estimated that approximately 96% of the generated questions are verifiable and unambiguous, corresponding to an annulment rate of about 4% (95% CI: 1.1% to 8.4%). For resolution, we use an ensemble of three Gemini 3 Pro agents with a Claude Opus 4.5 tiebreaker. Against a ground truth of 100 questions manually resolved by an expert, the system made 4 errors, giving an estimated accuracy of about 95%.
To validate the question set as a benchmark, we ran several LLM forecasters and confirmed that more capable models achieve better scores.
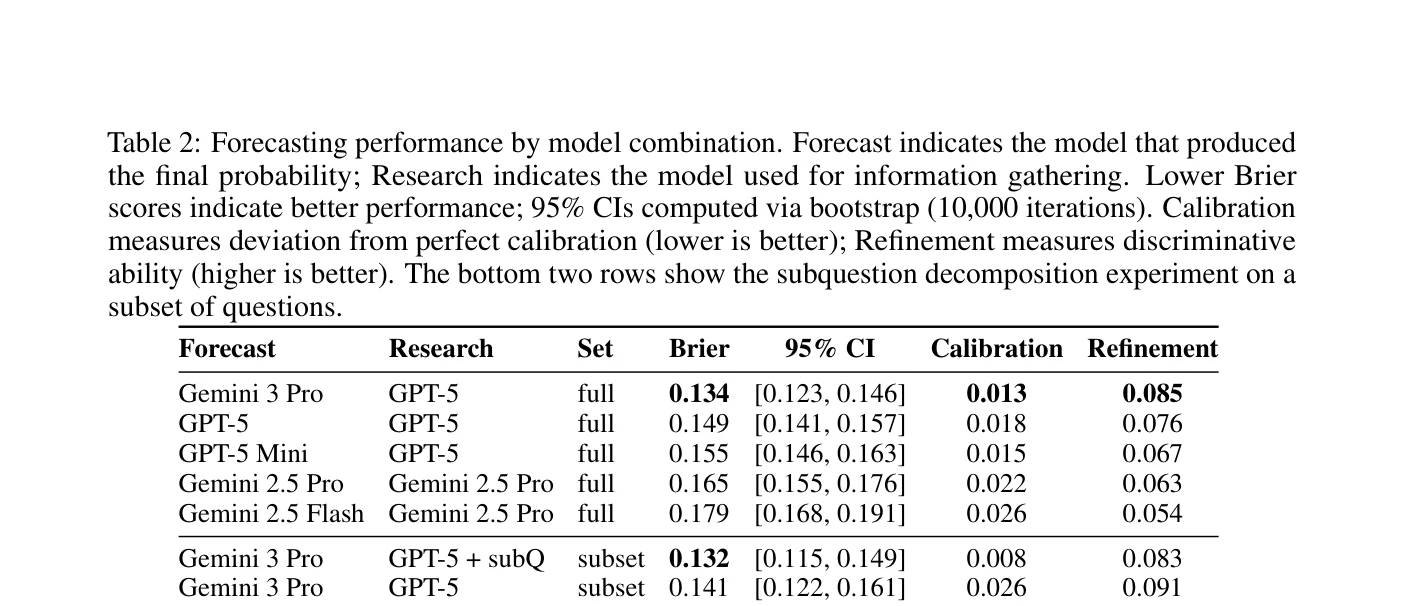
The model rankings are highly stable: in 10,000 bootstrap samples, Gemini 3 Pro ranks first 100% of the time, and GPT-5 ranks second in 99.1%. Larger models consistently outperform their smaller counterparts within the same family.
We also tested whether additional research effort helps beyond what a single frontier model can achieve. By "decomposing" questions into 3 to 5 subquestions, researching and forecasting on those, and feeding the results back into the final forecast, Brier scores improved from 0.141 to 0.132.
What We Learned
A few patterns stood out from inspecting questions and resolutions. Questions of the form "a large institution announced X; will X happen within 3 months?" almost always resolve NO, because institutions (particularly governments and the EU) operate on extended timelines. Resolving questions that require proving something did not happen is challenging for agents, especially for obscure bureaucratic events where absence of search results is not strong evidence. And model choice matters substantially for resolution quality: Opus 4.5 uses creative strategies like the Wayback Machine to verify data, while Gemini 3 Pro tends to accept search snippets at face value.
This work builds on our earlier benchmarks Deep Research Bench and Bench to the Future, and uses the ReAct agent implementation from Everyrow. The full paper, including all prompts used in the pipeline, is available on arXiv.