BTF-3 Leaderboard | DRB Paper | Bench To The Future
FutureSearch's actively maintained benchmark, with the latest frontier models, is BTF-3.
Deep Research Bench
Deep Research Bench (DRB) benchmarks how well LLM agents do research on the web. Each of the 91 real-world tasks provides 10-100k webpages stored offline for search and reasoning, accompanied by carefully curated answers.
Deep Research Bench has two features no other benchmarks of LLM-powered web agents have:
- Stores large chunks of the web offline, so results are stable even as the web changes
- The correct answers are carefully worked out, given the state of the web at that time, so scores are as objective as possible
Deep Research Bench is now featured on Epoch's Benchmark Hub.
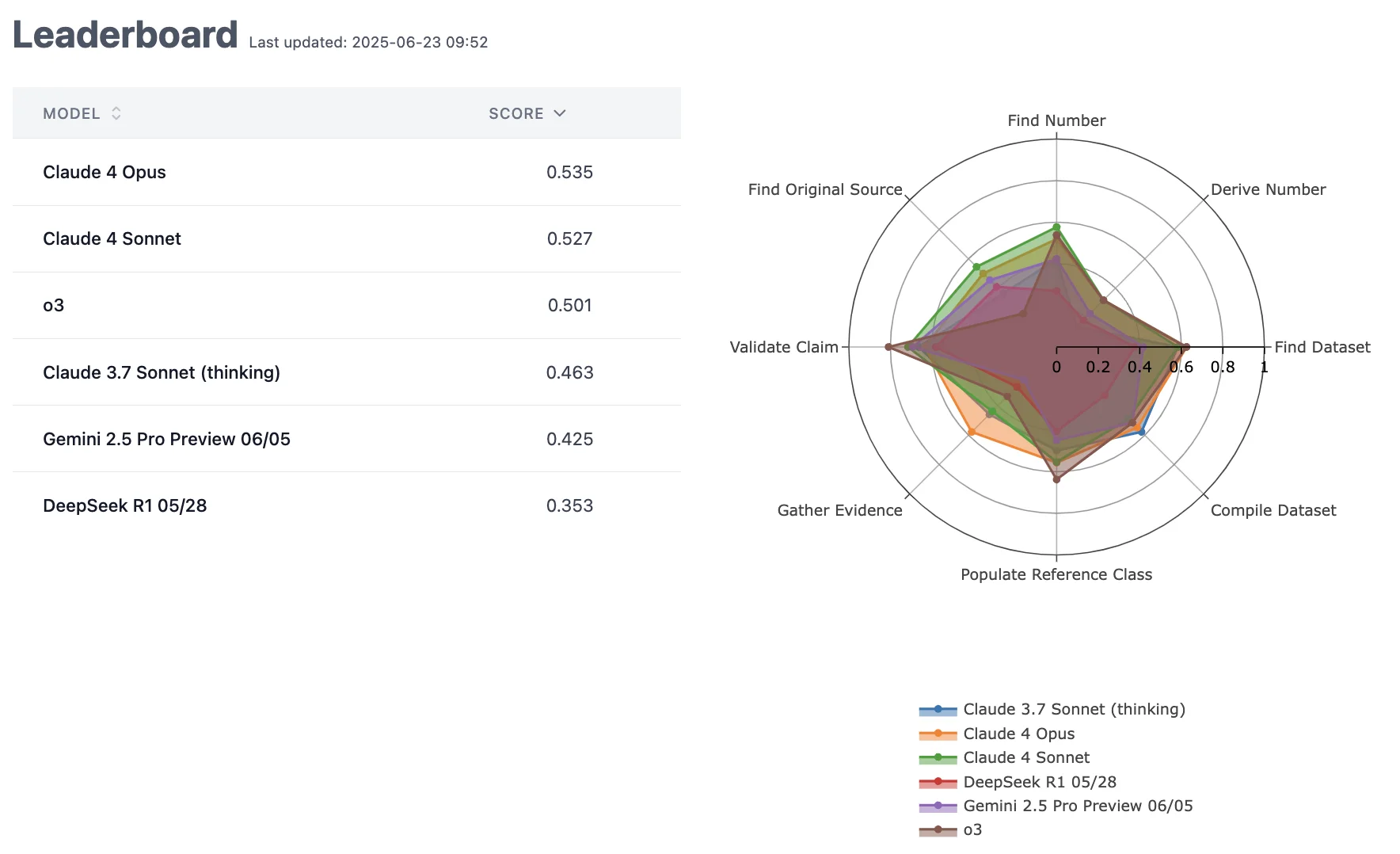
Leaderboard
We continuously update DRB, adding new tasks and models as they get released to the leaderboard.
Performance of Commercial LLM Research Tools
In addition to the regular "retro" evals on a frozen snapshot, we also evaluated several "live" commercial LLM research tools like OpenAI Deep Research or Perplexity on the May 2025 version of Deep Research Bench.
We found, for example, ChatGPT o3 to outperform all other approaches (including OpenAI Deep Research!) by a comfortable margin. For all details, see the paper.
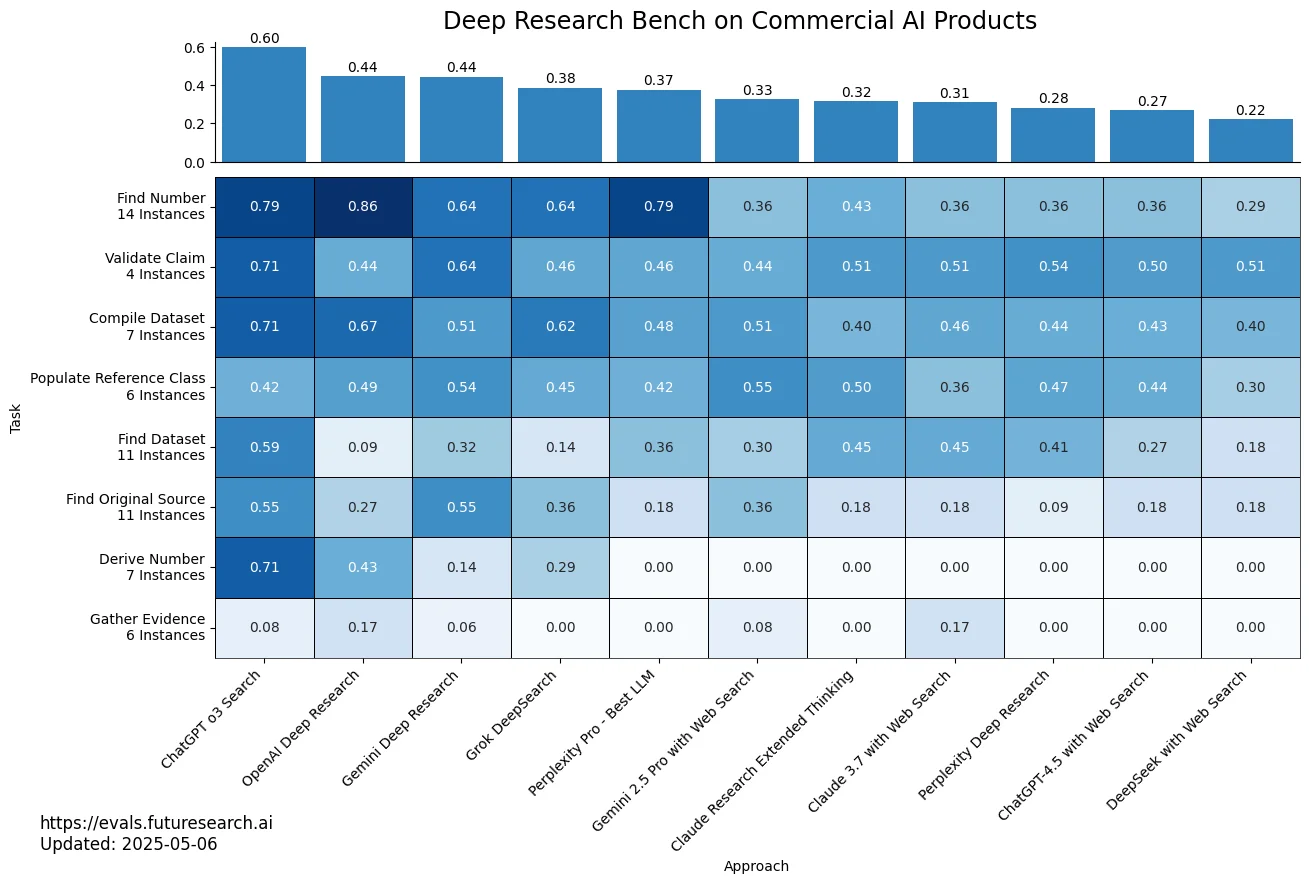
Scores across 8 task categories for various web research tools on the May 2025 version of DRB.
Related Reading
- Real-world evals of OpenAI's o1, the first "thinking" model
- OpenAI Deep Research: Six Strange Failures
- When should agents persist vs. adapt? Lessons from Deep Research
Press Coverage
- How Good Are AI Agents at Real Research? Inside the Deep Research Bench Report (Unite.AI, June 2, 2025)