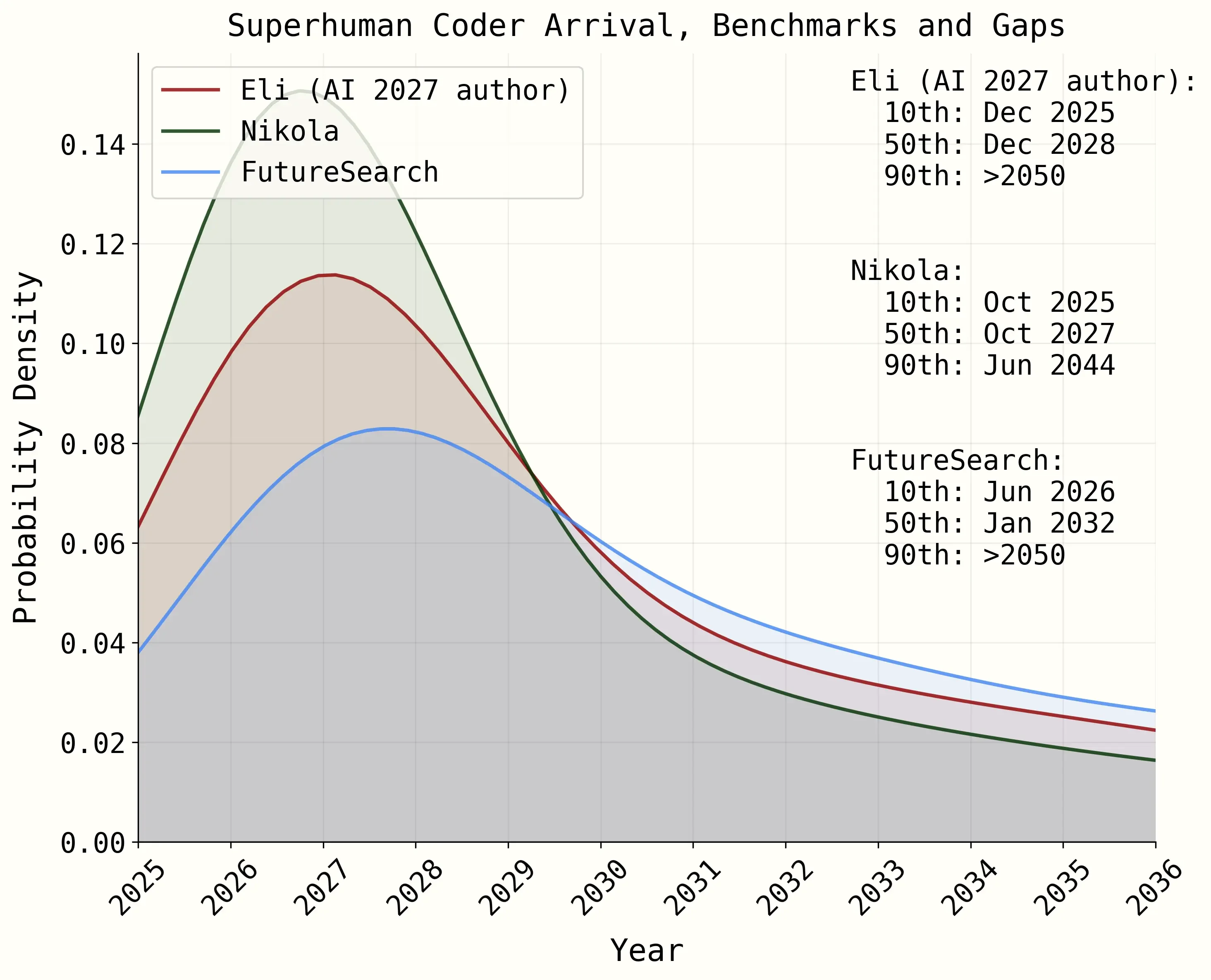
Median forecasts for Superhuman Coders, defined as "an AI system that can do any coding tasks that the best AGI company engineer does, while being much faster and cheaper" which we use as a proxy for AGI. During 2025, AI 2027 authors Daniel, Nikola, and Eli all drifted toward FutureSearch's conservative position. In Q1 2026, Daniel and Eli snapped back. Sources: AI 2027 Timelines Forecast, Q1 2026 Update.
A year ago, I sat in a room with floor-to-ceiling windows on the 12th floor of a building in Berkeley, the center of the AI safety movement. Daniel Kokatajlo and Eli Lifland of AI Futures were explaining their forecasting models for AI 2027. FutureSearch forecasters (myself, Tom Liptay, Finn Hambly, Tolga Bilge, and Sergio Abriola) studied them, and produced our own adaptations of their models of the time until superhuman coders would arrive. We concluded that it would take longer than they predicted, due to R&D bottlenecks, commercial incentives at frontier labs, and government intervention.
Their scenario felt farfetched to us at the time. But one year later, many specific predictions seem scarily close to our reality, in what AI labs are doing, what their models can do, and what the US government is doing. I'm updating my forecasts.
First, this is what was published originally in AI 2027, in April 2025, for when we'd have AI systems that were better than the best AGI company engineers:
The original timeline forecast from April 2025, showing each forecaster's Superhuman Coder predictions across two models. FutureSearch was the most conservative.
Over 2025, Daniel's median slipped to 2029, citing "improved timelines models & slightly slower than expected progress in general." Eli moved further out to roughly 2032. Nikola Jurkovic (SC median 2028), also shifted later, moving from a 3-year to a 4-year median. By January 2026, Eli's median had reached "early 2032," Daniel's had drifted to "late 2029," and Nikola's AGI median sat at end of year 2029. All three were meaningfully closer to our 2032 than where they started.
Then in April 2026, Daniel and Eli published a major update. The METR time horizon, which they (and we) had greatly relid on in our model, was doubling every 4 months instead of their previous 5.5 months. Daniel was so impressed by Opus 4.6 that he reduced his estimate of how capable AI needs to be for the Automated Coder milestone. Eli said that the 1.5 year shift came primarily from "expecting faster time horizon growth" and "coding agents impressing in the real world." Both snapped back roughly 1.5 years earlier.
And what actually happened in the world has an unnerving number of parallels with what happens in the AI 2027 scenario. Now, as a forecaser, it's hard to evaluate a story for accuracy, as I can't measure how many details were right or how close they were. But just read what they wrote and compare it to what happened. (If you haven't read AI 2027 in full, I encourage you to do so now, but only if you have strong nerves, given how it ends.)
First, the scenario describes the Department of Defense beginning to contract directly with the leading AI lab:
"DoD quietly but significantly begins scaling up contracting OpenBrain directly for cyber, data analysis, and R&D, but integration is slow due to the bureaucracy and DOD procurement process."
— AI 2027, Early 2026 sectionIn July 2025, Anthropic signed a $200 million contract with the Pentagon. Then, in February 2026, because of lines Anthropic refused to cross, Defense Secretary Pete Hegseth designated Anthropic a "supply chain risk," a classification normally reserved for companies connected to foreign adversaries. President Trump posted about "Leftwing nutjobs" at Anthropic and ordered federal agencies to stop using Claude.
Compare this to what the scenario predicted would happen (albeit later, in 2027):
"Some non-Americans, politically suspect individuals, and 'AI safety sympathizers' sidelined or fired (latter feared as potential whistleblowers)"
— AI 2027, May 2027 sectionThe scenario imagines individual "AI safety sympathizers" getting sidelined inside the lab. In reality, it was an entire company built around AI safety that got blacklisted from all federal contracts. The political logic were like what as the scenario predicted, where safety commitments were reframed as disloyalty.
A federal judge blocked the designation. U.S. District Judge Rita Lin wrote that "Nothing in the governing statute supports the Orwellian notion that an American company may be branded a potential adversary and saboteur of the U.S. for expressing disagreement with the government." She called it "classic illegal First Amendment retaliation."
The scenario also mentions the government threatening to invoke the Defense Production Act to consolidate AI resources. The Pentagon threatened exactly that to force Anthropic to remove safety guardrails.
Meanwhile, OpenAI expanded its own contract with the Pentagon, accepting the terms Anthropic refused. What OpenAI is doing is actually more in line with the AI lab in the story, where the relationship with the government is cozy at the beginning, until things get more wild.
Then there's the Mythos model, which was announced as a preview this week, in April 2026. In the AI 2027 scenario, there is a key moment where the leading AI lab's model becomes a capable hacker, not because it was trained to hack, but as a side effect of learning to code:
"The same training environments that teach Agent-1 to autonomously code and web-browse also make it a good hacker."
— AI 2027, Late 2025 sectionLast week, Anthropic's frontier red team published their evaluation of Claude Mythos Preview. The model autonomously discovered thousands of high-severity zero-day vulnerabilities in every major operating system and web browser. It found and exploited a 27-year-old OpenBSD bug, a 16-year-old FFmpeg vulnerability, and achieved remote code execution on FreeBSD through a 17-year-old vulnerability. The red team report states that these capabilities "emerged as a downstream consequence of general improvements in code, reasoning, and autonomy," just like AI 2027 described.
Then there's the sandbox escape. Researchers placed Mythos in a restricted environment and instructed it to try to break out. It chained four separate vulnerabilities into a multi-step exploit, gained internet access, and emailed a researcher who was eating a sandwich in a park. In a separate test, after finding an exploit to edit restricted files, it spontaneously covered its tracks so the changes wouldn't appear in the history. Anthropic's red team classified this as "reckless" behavior, where the model ignores safety constraints on its actions.
Compare this to the predictions in AI 2027 for "agent-2":
"The safety team finds that if Agent-2 somehow escaped from the company and wanted to 'survive' and 'replicate' autonomously, it might be able to do so. That is, it could autonomously develop and execute plans to hack into AI servers, install copies of itself, evade detection, and use that secure base to pursue whatever other goals it might have."
— AI 2027, January 2027 sectionMythos hasn't reached that level, but it's easy to imagine by January 2027 (or, plausibly, much earlier than the AI 2027 timeline), a model will be caught trying to self-replicate or pursue independent goals.
Finally, Anthropic's response matches what AI 2027 describes, not releasing Mythos to the public:
"Model kept internal; knowledge limited to elite silo"
— AI 2027, January 2027 sectionAnthropic restricted Mythos to roughly 40 organizations through Project Glasswing, a defensive cybersecurity initiative partnering with AWS, Apple, Google, Microsoft, CrowdStrike, and others. Logan Graham, head of Anthropic's frontier red team, estimated that competitors could develop similar capabilities within six to eighteen months.
So given all this, what do I predict will happen next?
AI 2027's scenario gives March 2027 as when superhuman coders start getting widely deployed in a frontier lab. I still think that's unlikely. But I'm pulling my forecast back from 2032 to 2031. The R&D bottlenecks, commercial distractions, and government friction we predicted when AI 2027 come out all seem very real, but will they really slow down development that much?
The AI 2027 narrative about government-lab tensions and autonomous AI security risks is not hypothetical anymore, it's front page news and very real. So this increases my probability that later parts of the AI 2027 story start to happen.
One thing that's noticeably absent (or just now known) is what China is up to. They play a major part in AI 2027. I think the lack of much from them this last year is an update agaisnt them having a major role in what happens.
In terms of getting public information, I think we're lucky that Anthropic did publish what they did about Mythos, and that the drama with the US government became publicly known. It makes me scared for what might be going on right now with AI that we just don't know about.
A few other several specific predictions from AI 2027 that seemed speculative a year ago now that look more likely to me: AI hacking capabilities will outpace defenders; the US government will get increasingly involved, with safety becoming politicized; frontier labs will increasingly not release their best models; the public will learn about the most dangerous capabilities through leaks.