Update, Oct 3 2025: In a forthcoming piece, we show that GPT-5's gross margins are significantly lower than the GPT-4 generation analyzed here.
Key Takeaways
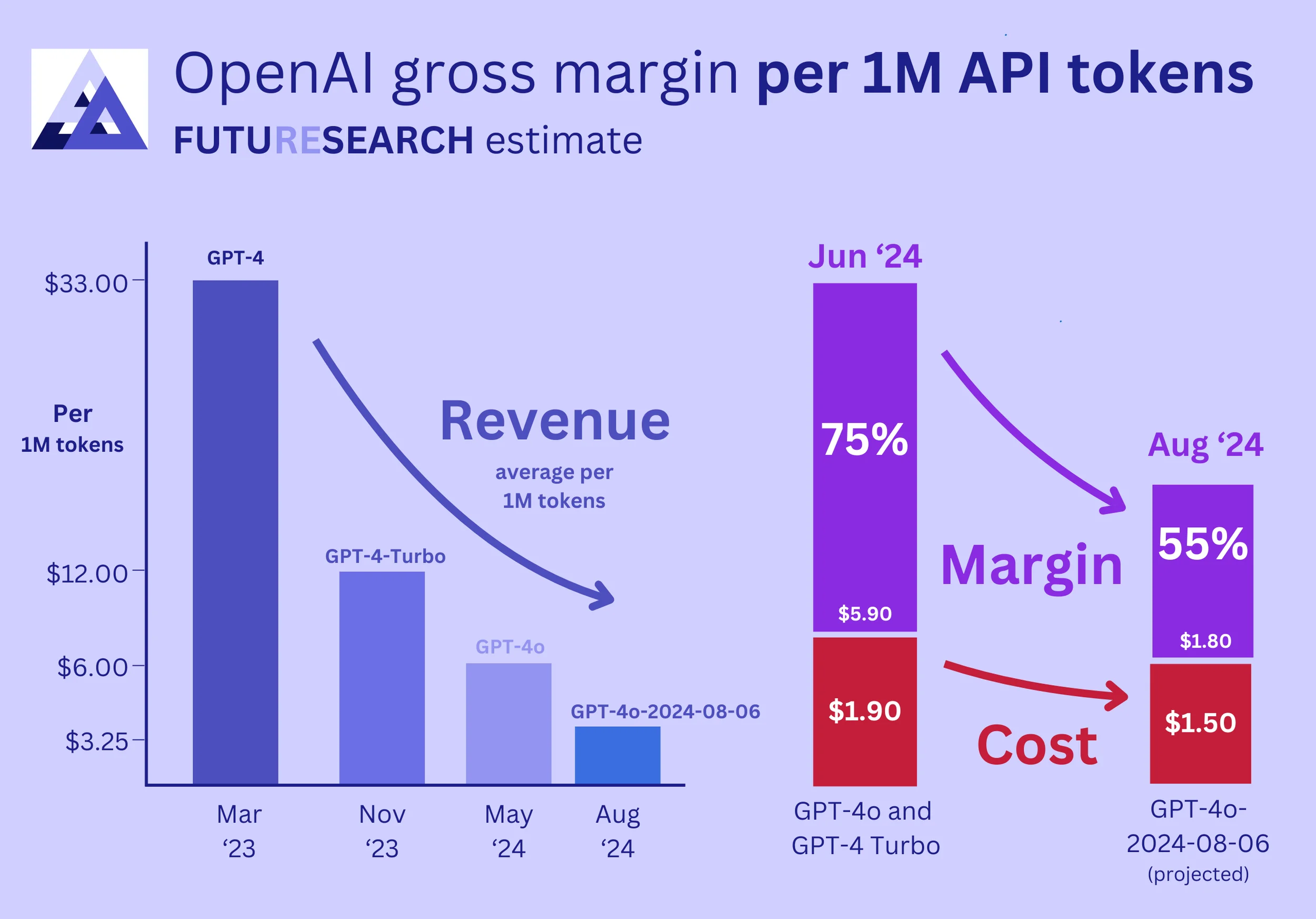
- OpenAI's API business had more favorable unit economics than commonly reported, with estimated gross profit margins around 75% as of mid-2024
- In June 2024, the API generated ~$41M in monthly revenue from ~530 billion tokens, with ~70% of traffic going to GPT-4o
- OpenAI rented approximately 12,300 A100-equivalent GPUs from Microsoft for the API at $1.30/hour, but operated at only ~38% utilization
- Unit economics for LLMs fundamentally depended on GPU cost savings through better memory usage, particularly improvements in memory bandwidth utilization
- In August 2024, FutureSearch became the first to rigorously work out OpenAI's gross API margins. For anyone modeling or forecasting LLM economics, this analysis of June 2024 data should be your anchor point.
This chart tells the whole story. OpenAI's API gross margins were around 75% in June 2024, decreasing to approximately 55% at August pricing. The key driver: costs fell even faster than prices.
In July 2024, The Information reported that OpenAI could face a $5 billion loss. However, our analysis showed OpenAI's API business had significantly more favorable unit economics than these reports implied.
This stood in sharp contrast to narratives suggesting unsustainable economics for the API business.

The bottom line: On $41.3M in June revenue, OpenAI earned roughly $31M in gross profit from the API.
The key insight is that unit economics for large language models came down to saving on GPU costs through better memory usage. As OpenAI continued optimizing memory bandwidth utilization, profit margins remained healthy despite aggressive pricing competition.
Revenue Was Falling, Not Rising
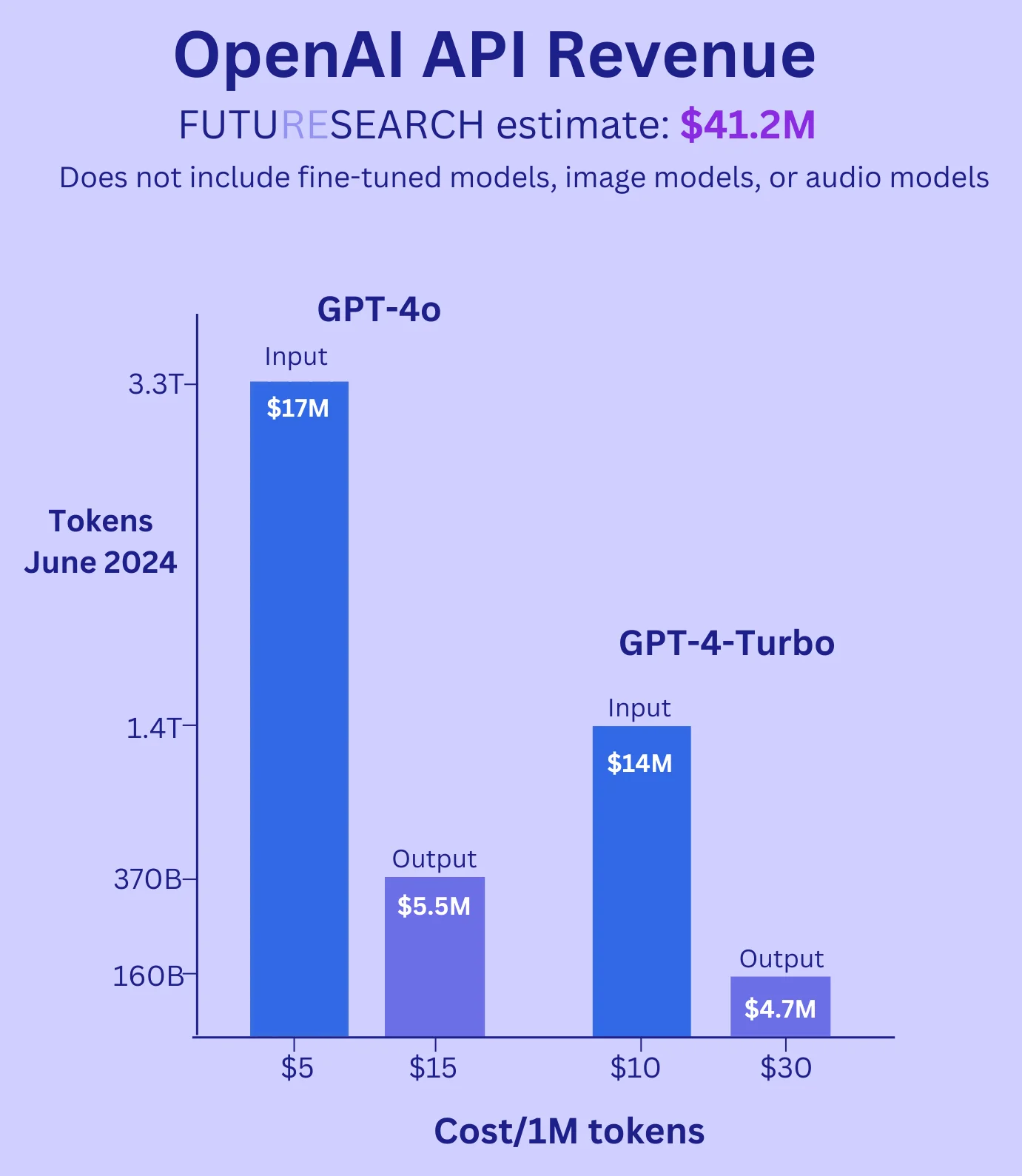
Despite growing traffic, API revenue was declining. We estimated API Annual Recurring Revenue (ARR) at approximately $500M in mid-2024, down from higher levels earlier in the year.
While API traffic had grown, revenue decreased faster than traffic increased due to aggressive price reductions throughout 2024. This revenue decline reflected OpenAI's strategic choice to prioritize market share and developer adoption over short-term revenue maximization. The August 2024 model pricing updates further accelerated this trend, with significant price cuts across GPT-4o and other models.
This revenue pressure is why understanding GPT-5's economics matters—see our September 2025 update above. The declining revenue trajectory created an interesting dynamic when combined with OpenAI's overall revenue breakdown, where the API represented a smaller portion of total ARR than consumer ChatGPT products.
Memory Bandwidth: The Critical Constraint
The fundamental constraint on LLM inference profitability was memory bandwidth, not raw compute. Modern GPUs were increasingly memory-bound when serving LLM requests, meaning improvements in memory utilization directly translated to better unit economics.
For GPT-4 on 8-way tensor parallelism:
- Reading KV cache: 6×10⁻⁴ seconds per token
- Reading model weights: 2×10⁻⁵ seconds per token
- Bottom line: ~45,000 tokens per A100 per hour
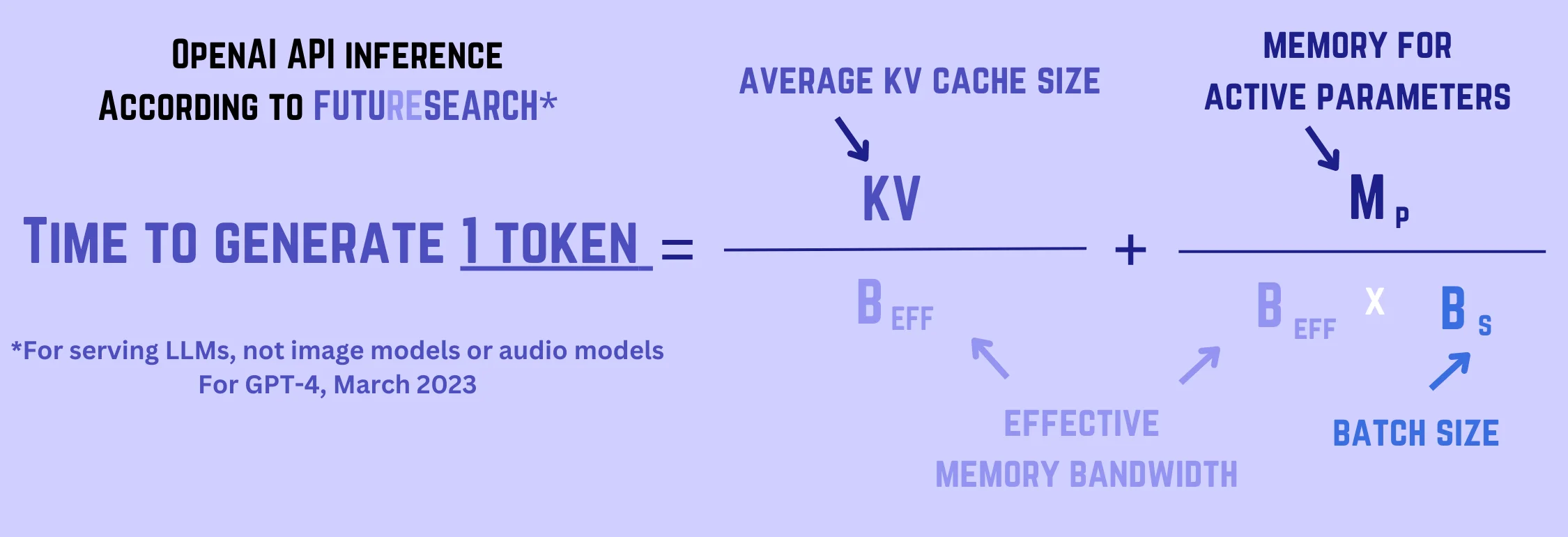
This calculation shows why improvements in memory efficiency directly translated to better unit economics.
Key technical insights:
- Memory constraints limited compute capability - GPUs spent more time waiting for memory than performing calculations
- Improvements between GPT-4 models suggested significant memory optimization gains
- Sparse attention techniques and other architectural improvements could dramatically reduce memory bandwidth requirements
These technical factors explained why unit economics continued improving despite price competition. As model architectures became more memory-efficient, the cost per token served decreased faster than prices fell.
For the detailed calculation behind these numbers, see "Why 28 A100-Hours per Million GPT-4 Tokens?" below.
Key Numbers At a Glance
June 2024 API Revenue & Traffic:
- June 2024 API Revenue: $41.3M
- Tokens generated in June: 530 billion
- Input tokens processed: 4.7 trillion
- Input to output ratio: 9:1
- Traffic to GPT-4o: 70%
GPU Infrastructure & Utilization:
- A100-equivalents rented from Microsoft: 12,300 GPUs
- Cost per A100 hour: $1.30
- GPU utilization: 38%
- Monthly API growth rate: 10%
- Overprovisioning time horizon: 3 months
- Typical avg to max daily traffic ratio: 2:1
Compute Efficiency Improvements:
- GPU hours to generate 1M tokens with original GPT-4: 28 A100-hours
- Compute reduction GPT-4 → GPT-4 Turbo: 65%
- Compute reduction GPT-4 → GPT-4o: 82.5%
Technical Specifications:
- GPT-4 parameters per forward pass: 280B
- A100 memory bandwidth: 2TB/s
- A100 memory capacity: 80GB
- GPT-4 inference pipeline parallelism: 16
- GPT-4 inference tensor parallelism: 8
- Average input tokens: 2,200

These numbers anchor our calculations below.
How We Worked It Out
Here's how we arrived at the 75% margin figure, and why we're confident in these estimates.
We defined profit as revenue from serving API traffic minus the costs to serve that traffic on GPUs rented from Microsoft Azure. This calculation proceeded in two steps:
- Calculate total cost for serving the API in June 2024
- Use June cost and revenue to calculate the new profit margin after the release of gpt-4o-2024-08-06
The June 2024 Margin: 75%
Our approach: Revenue minus GPU costs.
Step 1: Revenue
In our previous revenue analysis, we estimated ARR from the API for June at $496M (out of $3.4B total ARR including ChatGPT Plus, Team, and Enterprise), yielding monthly API revenue of $41.3M.
Step 2: How much compute was needed?
GPT-4o was released mid-May 2024, so by June we estimated 70% of API traffic had shifted to GPT-4o, with 30% remaining on GPT-4-Turbo. Dividing June's 530B output tokens between the two models:
- GPT-4o output tokens: 0.7 × 530B = 371B
- GPT-4 Turbo output tokens: 0.3 × 530B = 159B
For cost calculations, we worked in terms of A100 hours and defined cost as the cost to rent enough A100s from Microsoft to meet demand:
A100 inference cost = (Cost per A100 hour) × (A100 hours to generate tokens) / (Utilization of rented A100s)
We estimated that producing 1M tokens for the original GPT-4 model required 28 A100-hours (see "Why 28 A100-Hours per Million GPT-4 Tokens?" below). Compared to GPT-4:
- GPT-4o required 82.5% less compute (0.175× the original compute)
- GPT-4 Turbo required 65% less compute (0.35× the original compute)
Adapting the original 28 hours required to produce 1M GPT-4 tokens:
A100 hours to generate tokens = (371B GPT-4o tokens × 0.175 × 28 / 1M) + (159B GPT-4 Turbo tokens × 0.35 × 28 / 1M) = 0.175 × 28 × 371K + 0.35 × 28 × 159K ≈ 3.4M A100 hours
Step 3: What did that compute cost?
With the 38% utilization rate (see "Why 38% GPU Utilization?" below) and $1.30/hour to rent an A100 (reported by The Information):
A100 inference cost = (3.4 million hours / 0.38) × $1.30 ≈ $11.6M
Adjusting for H100 usage: OpenAI likely performed some inference on H100s for superior efficiency. Assuming 20% of inference was on H100s, and with Semianalysis reporting ~60% cost savings for H100 vs A100 inference:
Inference cost = $11.6M × (0.8 + 0.4 × 0.2) ≈ $10.2M
Result: On $41.3M of revenue, this gave a June 2024 API profit margin of around 75%.
To achieve this, OpenAI used the equivalent of approximately 12,300 A100s in June 2024. Dividing the estimated 3.4M A100 hours required by 24 hours/day and 30 days gave 4,700 A100 equivalents assuming constant average load. With the realistic 38% utilization to handle traffic variability, this scaled to ~12,300 A100 equivalents.
The August 2024 Margin: 55%
New pricing: 50% cut on input tokens, 33% cut on output tokens (gpt-4o-2024-08-06).
The profit margin once all traffic switched to gpt-4o-2024-08-06, priced at 1/2 for input tokens and 2/3 for output tokens compared to the May 2024 gpt-4o.
Why we thought this was competition-driven (not cost-driven): While the price drop from GPT-4-Turbo to GPT-4o (>7 months) likely matched cost reductions from algorithmic and hardware improvements, the subsequent GPT-4o price drop (under 3 months later) appeared driven by competition from Claude-3.5-Sonnet and Llama-3.1-405b.
New revenue per token:
Revenue per output token = 9 × $2.5×10⁻⁶ + $10×10⁻⁶ = $32.5×10⁻⁶
Same cost per token:
Cost per output token = $1.30 × (28 × 0.175 / 0.38) × (0.8 + 0.4 × 0.2) ≈ $14.75×10⁻⁶
Result:
Profit margin = (Revenue per output token - Cost per output token) / Revenue per output token = ($32.5×10⁻⁶ - $14.75×10⁻⁶) / $32.5×10⁻⁶ ≈ 55%
Why 28 A100-Hours per Million GPT-4 Tokens?
We started with a first-principles calculation based on leaked architecture details, then adjusted for real-world factors.
The basic calculation:
We analyzed the GPT-4 architecture and inference setup leaked in mid-2023, assuming 8-bit inference.
Key simplification: We assumed prefill time (processing input tokens) was negligible compared with generation time, so input tokens affected results only via their impact on memory reads during generation.
Memory bandwidth was the bottleneck: Token generation was bottlenecked by memory bandwidth. Memory access was dominated by KV-cache reads and model-weight reads. Since token generation was done in batches, the average time to generate a token equaled the average time to generate a batch divided by batch size.
Time to read weights or cache entries equaled the memory footprint divided by memory bandwidth. The assumed inference setup involved 8-way tensor parallelism, giving an effective memory bandwidth 8× that of a single A100 (2TB/s), i.e., 16TB/s.
KV cache read time: Using leaked architectural details, the KV cache for a single token at a single layer took approximately 40KB. With our internal queries as representative (average 2,200 input tokens), the average query's KV cache took up about 10GB, giving a read time of approximately 6×10⁻⁴ seconds per sequence:
Time to read KV cache per token = (Average KV cache size) / (Effective memory bandwidth) = 10GB / 16TB/s ≈ 6×10⁻⁴ seconds
Model weight read time: GPT-4-0314 used 280B parameters during inference, so 280GB needed to be read, taking 1.75×10⁻² seconds. Dividing by the average batch size (approximately 810, calculated from available memory divided by space per query):
Time to read model weights per token = (Memory for active parameters) / (Effective memory bandwidth × Batch size) = 280GB / (16TB/s × 810) ≈ 2×10⁻⁵ seconds
Summing the two contributions gave approximately 6.2×10⁻⁴ seconds to generate a token. Since 128 A100s were required, this translated to 12.6 tokens/second/A100, or 45K tokens/hour/A100. Thus:
A100-hours to generate 1M tokens ≈ 22
Adjustments for reality:
We adjusted this anchor to account for:
-
Batching efficiency: OpenAI's actual batching implementation might not achieve the "smooth" batching assumed above. Given the heavy API load (>800 QPS) and multi-second query processing times, we applied a +25% upward adjustment.
-
Bottleneck assumptions: If memory bandwidth wasn't the true bottleneck, our calculation would overestimate throughput. We applied a +20% upward adjustment.
-
Semianalysis estimate: The semiconductor blog estimated higher throughput (~60 tokens/A100/sec) using detailed simulation, though with unclear utilization assumptions. They noted that under less generous assumptions, their cost estimate would more than double. We applied a -15% downward adjustment.
Overall, we applied a net +27.5% adjustment, obtaining:
A100-hours to generate 1M tokens ≈ 28
Why 38% GPU Utilization?
Cloud services need spare capacity for two reasons.
Reason 1: Daily traffic swings
OpenAI had to provision GPUs to handle maximum API traffic on a typical day. We estimated this variation by:
- Starting with typical 2× daily variation in cloud service traffic
- Adjusting upward to 3× given OpenAI's geographic bias toward US and European usage, implying more traffic during US/European working hours than most global cloud services
3× peak-to-trough variation implied 2× overprovisioning above what was needed for average load.
Reason 2: Planning for growth
Cloud providers typically provision for growth. While details of OpenAI's Microsoft GPU rental agreement were unclear (The Information reported Microsoft set aside 350k GPUs for OpenAI for inference, 60k for non-ChatGPT/API use), we estimated OpenAI provisioned for 3 months of projected API growth.
Given API usage increased by ~10% monthly between December 2023 and June 2024 (ignoring GPT-4o's mid-May release), 3-month growth would be:
Growth over 3 months = (1 + 0.10)³ ≈ 1.33 (33% growth)
Combined: Assuming 2× overprovisioning for daily variation and 1.33× overprovisioning for short-term growth:
Utilization = 1 / (2 × 1.33) ≈ 38%
What This Means Going Forward
Two Future Scenarios
Scenario 1: Intensifying Competition
In this scenario, competition from Anthropic, Google, and others drives continued price drops through 2025. However, margins likely remain above 50% due to:
- Ongoing memory bandwidth optimizations
- Economies of scale in GPU procurement
- Architectural improvements in model serving
Even under aggressive price competition, the fundamental unit economics remain viable as infrastructure costs decline faster than prices.
Scenario 2: Quality Differentiation
Alternatively, OpenAI could maintain premium pricing through model quality differentiation. If GPT-5 or future models demonstrate substantial capability improvements, they could command higher prices while maintaining strong adoption.
This scenario depends on OpenAI's ability to maintain a meaningful quality lead over competitors, which has historically proven difficult to sustain in technology markets. However, the path to superintelligence may create periods where quality differentiation enables pricing power.
Implications for OpenAI's Business Model
The API profitability analysis revealed several strategic implications:
Consumer focus justified: With consumer products generating the majority of revenue and better unit economics than previously reported for the API, OpenAI's consumer-first strategy made business sense.
Pricing flexibility: Healthy margins provided room for continued price reductions to capture market share without threatening business viability.
Infrastructure advantage: Excess GPU capacity and improving memory utilization created a sustainable competitive moat against smaller competitors who lacked similar infrastructure scale.
Revenue diversification: The combination of strong consumer revenue and profitable (if declining) API revenue provided financial stability as the company scaled toward ambitious 2027 revenue targets.
Related Reading
- The First Full OpenAI Revenue Breakdown - Complete revenue analysis across all product lines
- OpenAI's Revenue in 2027: A Comprehensive Forecast - Long-term revenue projections
- OpenAI's financials: a Case Study of claims vs. reality - Validation of revenue estimates