Deep Research Bench tracks cost and runtime alongside accuracy for every model we evaluate. We plot Pareto frontiers—curves where no other model is both cheaper (or faster) and more accurate—to find the best trade-offs across 20+ LLM research agents. (All plots are from our Pareto analysis notebook.)
Best Accuracy per Dollar
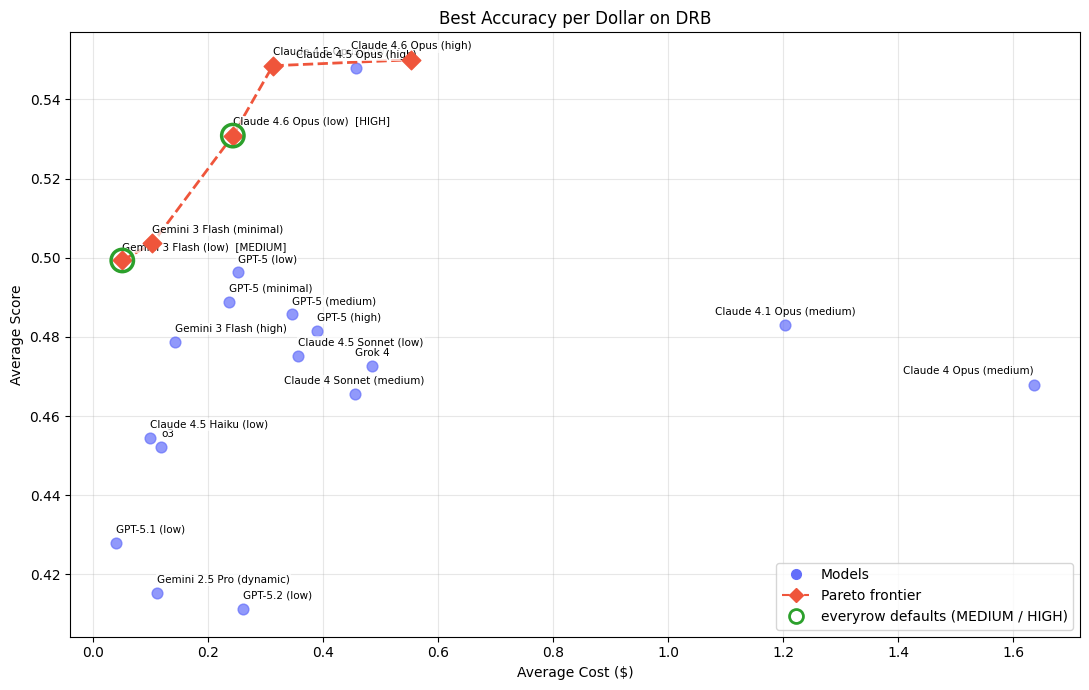
The cost frontier runs from Gemini 3 Flash (low) at just $0.05/task through Claude 4.6 Opus (low) at $0.24 (53.1% accuracy) to Claude 4.6 Opus (high) at $0.55 (55%), which tops the leaderboard. Most models cluster well under a dollar, making deep research surprisingly affordable.
Green rings mark the models powering everyrow's MEDIUM and HIGH effort levels—both sit on or near the Pareto frontier.
Best Accuracy per Second
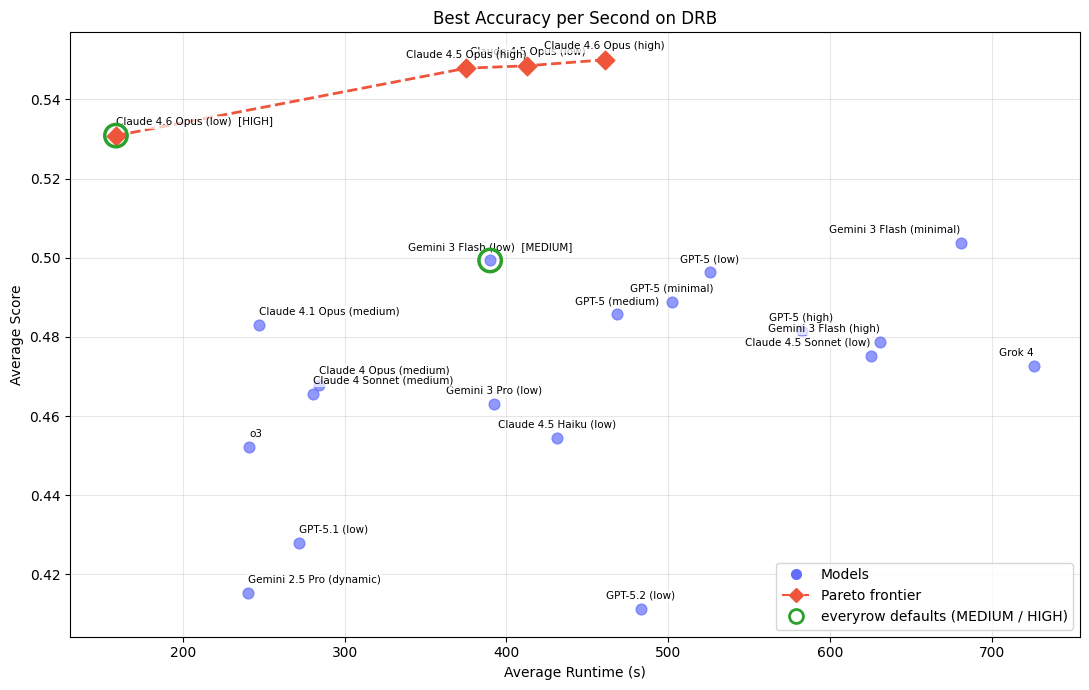
On wall-clock time, Claude 4.6 Opus (low) dominates: it's the fastest frontier model (~130 s) and the second-most accurate overall. Claude 4.6 Opus (high) takes about 6 minutes to finish a task, but edges ahead on score.
Note: wall-clock times partly reflect the token-per-minute and rate limits we had access to during evaluation, which vary by provider and tier. Your runtimes may differ depending on your own API limits and how much you ran concurrently.
Takeaway
The "best" model depends entirely on your constraint. If you want maximum accuracy and don't mind $0.55/task, Claude 4.6 Opus (high) wins. If you want fast and cheap, Gemini 3 Flash is hard to beat. And if you want the best all-around trade-off, Claude 4.6 Opus (low) sits on both frontiers—it's everyrow's default for HIGH effort.
Check the live leaderboard at evals.futuresearch.ai for the latest numbers—we keep it current as new models ship.