Paper | Live Deep Research Bench Leaderboard
Key Takeaways
- OpenAI's o1 model, the first thinking/reasoning model to be made commercially available, was able to solve some new complex tasks no non-thinking model at the time could solve
- OpenAI o1 and Claude Sonnet 3.5 significantly outperformed other LLMs including GPT-4o on complex real-world tasks
- o1 shows high variance: sometimes completely aces tasks others struggle with, but often performs average
- Most agents made meaningful progress but fell short of good end-to-end performance on all but the simplest tasks
- Llama 3.1 405B and GPT-4o-mini showed limited usefulness for multi-step agent tasks
Evaluating LLMs on Real-World White-Collar Tasks
We evaluated traces line-by-line of openai-o1, gpt-4o, claude-sonnet-3.5, and llama-405b, with several agent architectures, on 8 real-world, white-collar tasks where we knew all the details of what it takes to succeed.
The result? In the words of one of our research scientists: "o1 is very impressive, but pretty moody… sometimes it works great and (almost) completely aces something all other agents struggle with, but often it's distinctly average."
Bottom line: Take o1 for a small chance to go all the way and Sonnet for more consistent performance; gpt-4o is not quite there whereas llama-405b and gpt-4o-mini are barely useful as agents completing tasks that require tool use and 10+ prompted decision points for updating their plans.
Our Evaluation Methodology: Messy White-Collar Tasks with Partial Credit
Our eval is unique in that it is done on "messy" white-collar tasks inspired by work for our customers, and that we have sophisticated partial scores for progress on the numerous things to get right and get wrong.
The tasks were of the nature:
- Tracking down the original source of a claim
- Compiling a list of AI labs that have trained large models
- Figuring out the time after a virus emerged before the first seroprevalence study was published
Example Task: Estimating Chinese Disposable Income Over 100,000 Yuan
One detailed example task involved estimating the number of Chinese people with more than 100,000 Yuan annual disposable income. This task demonstrated o1's unique approach of breaking tasks into well-defined subtasks and its ability to adapt plans and reject poor data sources.
The evaluation used a sophisticated partial credit scoring system that assessed progress across multiple dimensions, allowing us to measure meaningful advancement even when agents didn't achieve complete success.

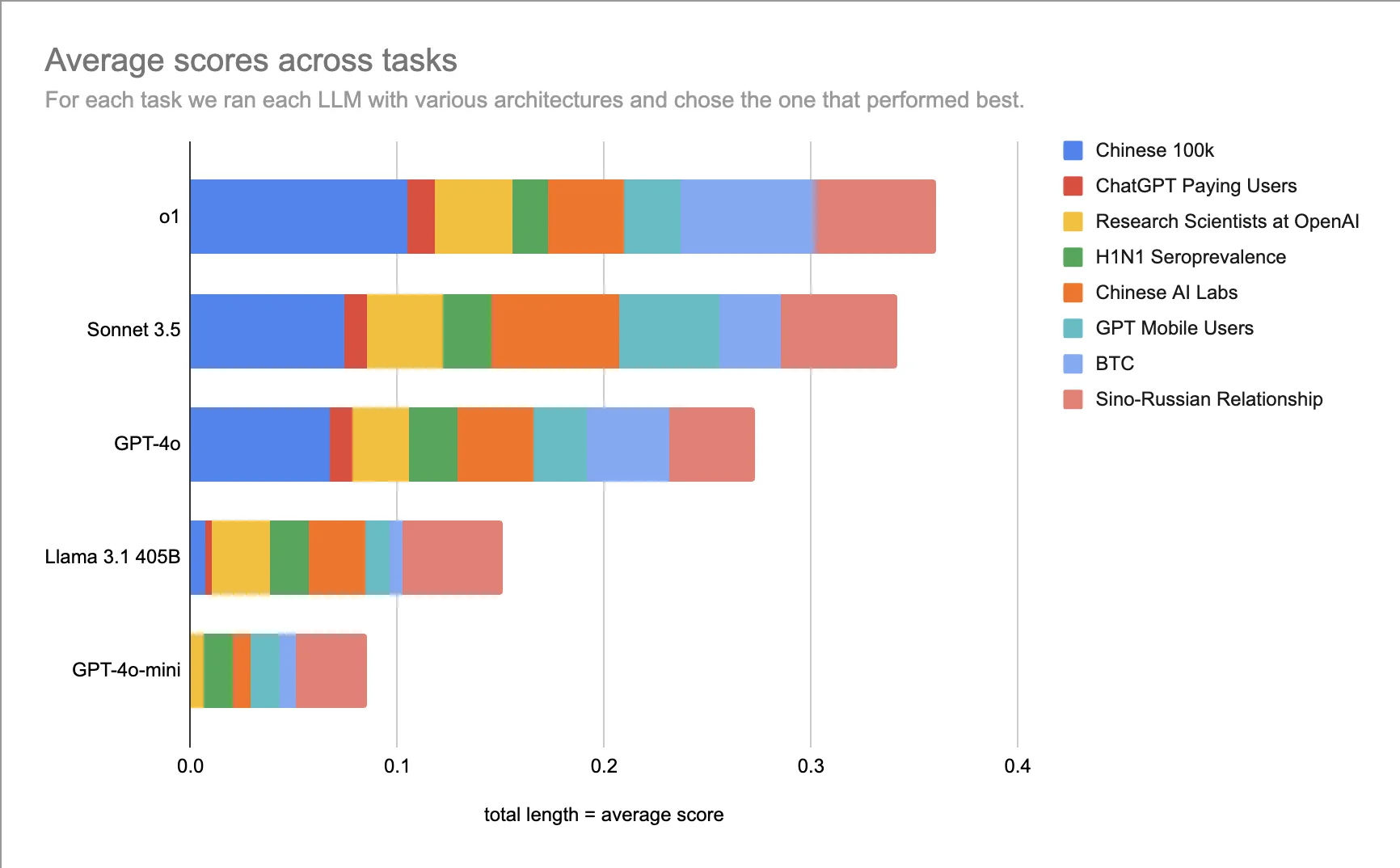
Results: o1 and Sonnet Lead, But End-to-End Performance Remains Challenging
Main Findings
- Agents made meaningful progress on tasks of economic value, but fell short of good end-to-end performance on all but the simplest of tasks
- OpenAI o1-preview and Claude Sonnet 3.5 noticeably outperformed other LLMs, including GPT-4o
- On average, Sonnet 3.5 was better than o1-preview
- But if you could choose the right architecture for each question—something you would do if the tasks were paid—o1 was better
- Both Llama 3.1 405B and GPT-4o-mini were not able to make meaningful progress on most of the tasks
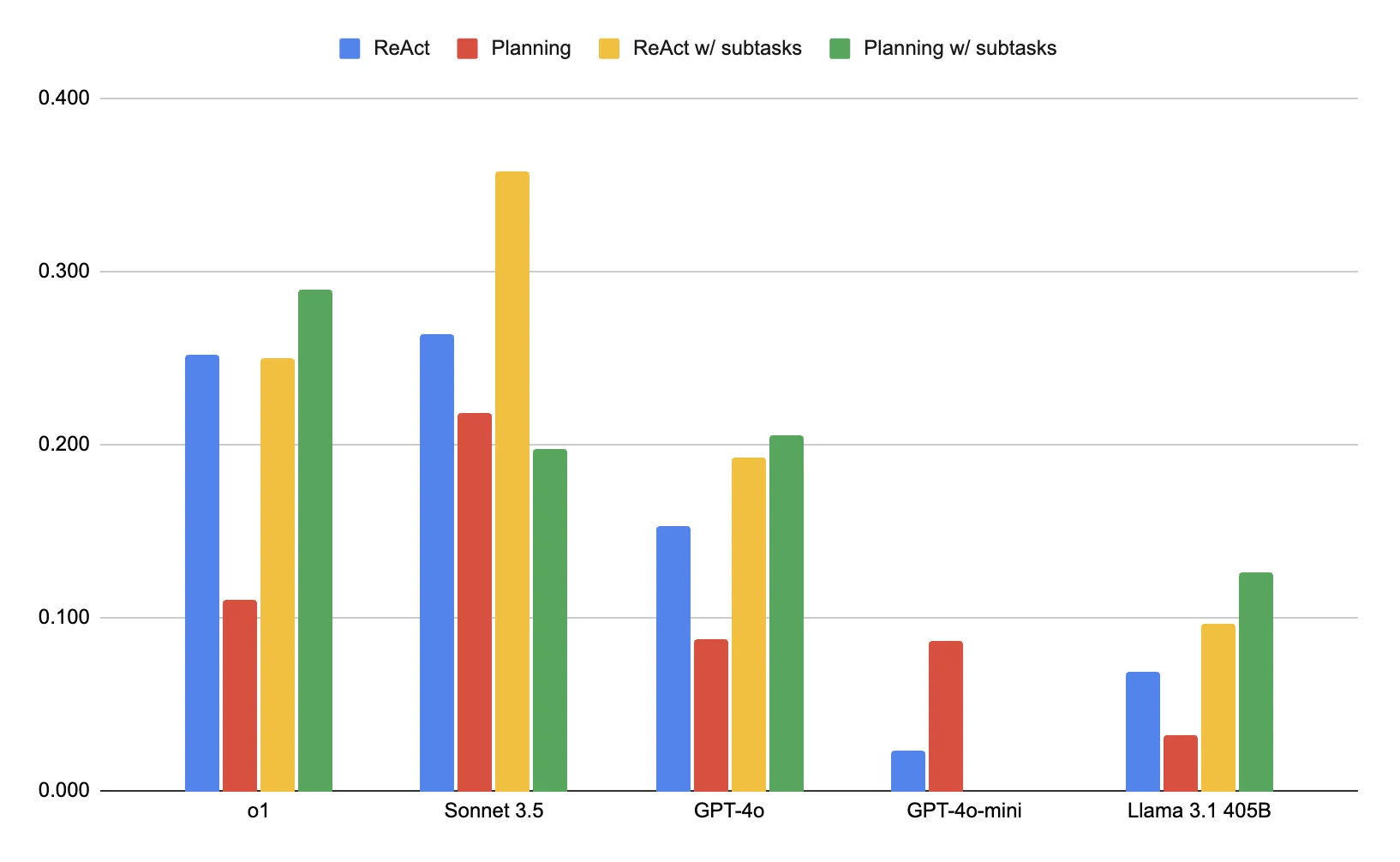
- There was significant variation in success with [Architecture x LLM] pairs. Overall, a ReAct agent with the ability to delegate subtasks performed best
Practical Recommendations
For teams deploying LLM agents on complex research tasks, our findings suggest a two-pronged strategy: deploy o1 for high-value tasks where breakthrough performance justifies the variance, and rely on Sonnet 3.5 for workflows requiring predictable, consistent results.