Previously we wrote how we use LLMs to deduplicate data. But that was 200 rows. So we asked, can we scale this up 100x? Then worked to keep the cost low, while still correctly matching rows using semantic knowledge, even when each row has 20,000 potential rows to match again.
Results
Experiment 1 (FDA drug products, 20,000 rows):
- F1 (precision & recall) = 0.996
- ~11,000 LLM calls, in a single 25 minute run, no failures
- Cost ~$1.12 per 1,000 rows
Experiment 2 (company names, 8,628 rows):
- F1 = 0.976, robust across entity types
- Cost scales linearly and predictably
We also tested on 5 additional datasets across people, transactions, and products with different equivalence rules, to be sure the LLMs were solving this fully generally.
Scaling Experiment 1: FDA Drug Products
A synthetic dataset based on the FDA Approved Drug Products database, tested at increasing sizes (500 to 20,000 rows) with a 10% duplicate rate. Each row contains a trade name, active ingredient, applicant, strength, and dosage form. Duplicates are created through typos, abbreviation changes, and reordering, the kind of variation that defeats exact matching but is obvious to a human reader.
Same ingredient + same strength + same applicant + same dosage form = duplicate. Products must match on ALL four fields.
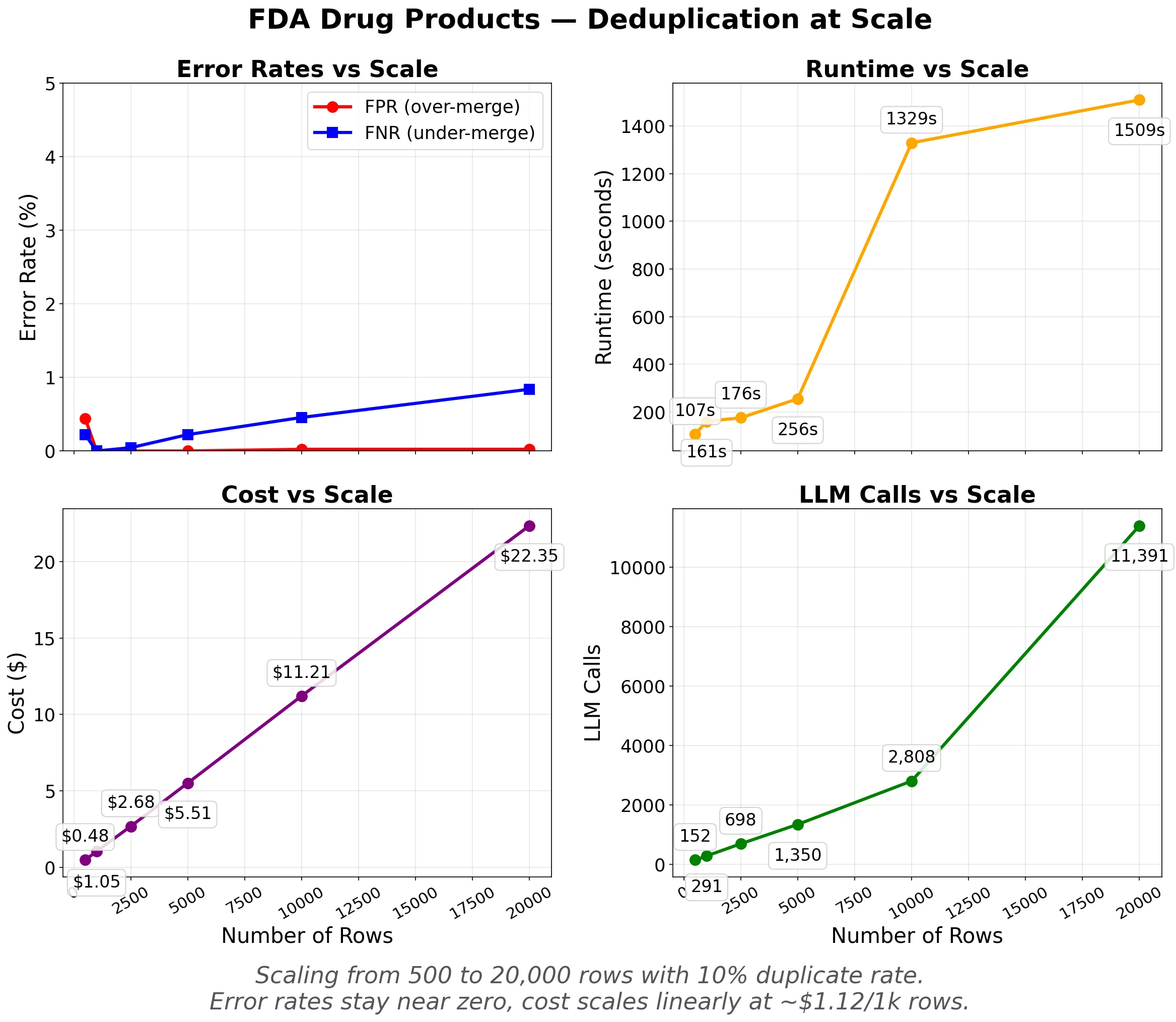
The FDA dataset shows near perfect precision across all sizes, the system almost never incorrectly merges distinct products. The false negative rate (missed duplicates) stays below 1% even at 20,000 rows. Cost scales linearly at approximately $1.12 per 1,000 rows.
| trade_name | ingredient | applicant | strength | dosage_form |
|---|---|---|---|---|
| IRBESARTAN | IRBESARTAN | CHARTWELL RX | 75MG | TABLET;ORAL |
| TRIKAFTA (COPACKAGED) | ELEXACAFTOR, IVACAFTOR, TEZACAFTOR; IVACAFTOR | VERTEX PHARMS INC | 100MG,75MG,50MG; 150MG | TABLET;ORAL |
| QUETIAPINE FUMARATE | QUETIAPINE FUMARATE | MEDICAP LABS | EQ 50MG BASE | TABLET, EXTENDED RELEASE;ORAL |
| MINOCYCLINE HYDROCHLORIDE | MINOCYCLINE HYDROCHLORIDE | SUN PHARM INDUSTRIES | EQ 75MG BASE | TABLET;ORAL |
Scaling Experiment 2: Company Names
A synthetic dataset of company names at increasing sizes (500 to ~8,600 rows) with a 10% duplicate rate. Duplicates are created through abbreviations (Inc to Incorporated), case changes, punctuation removal, and minor typos, the kind of real world variation found in CRM exports and financial data.
Same company = same legal entity.
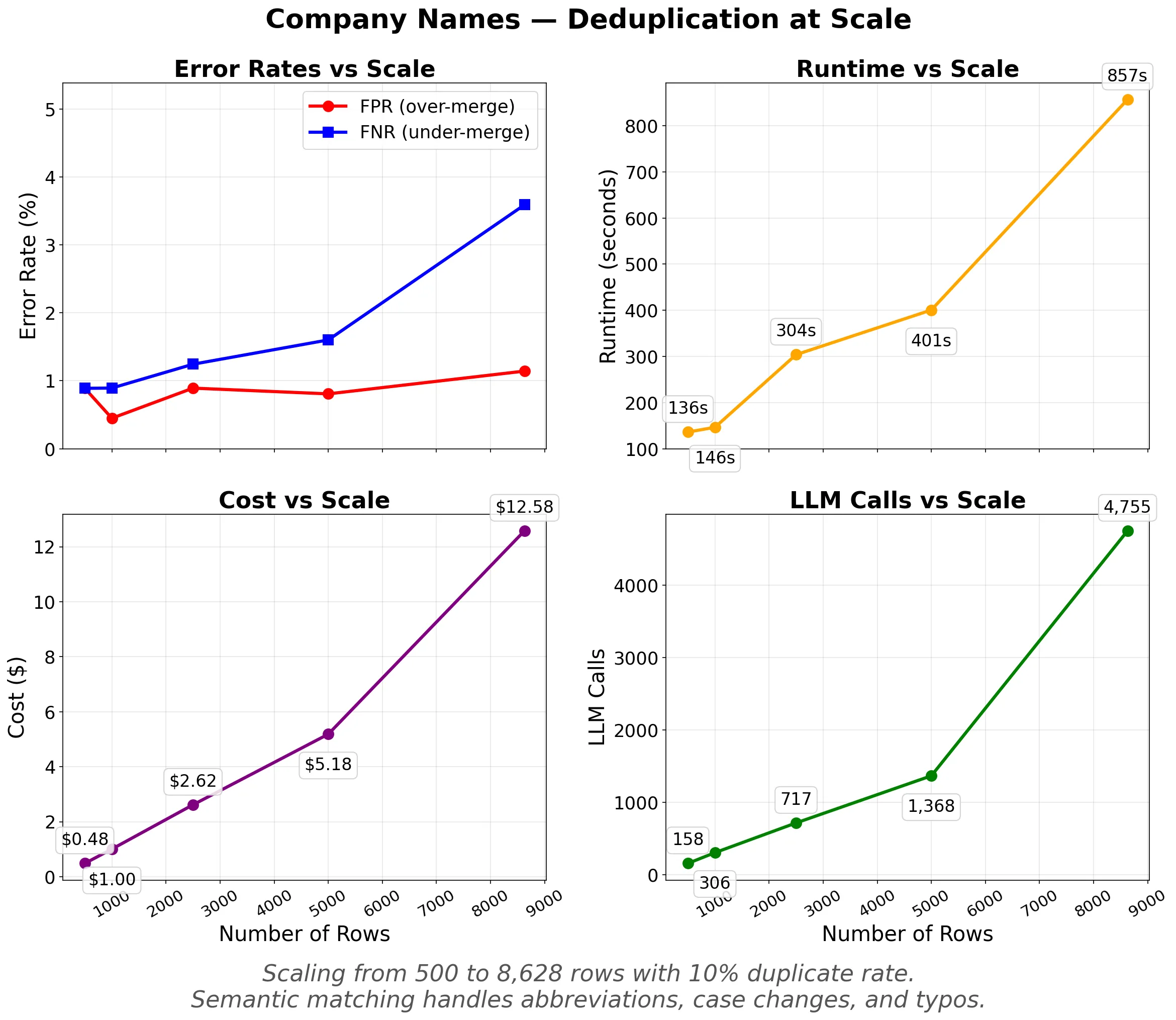
Company name deduplication is inherently harder than structured pharmaceutical data. With only a name and sector to work with, the system must make semantic judgments: is "AXON ENTERPRISE, INC." the same as "Axon Enterprise Inc"? (Yes.) Is "VIRTU FINANCIAL INC CLASS A" the same as "VIRTU FINANCIAL INC"? (Depends on the rule.) Despite this ambiguity, F1 stays above 0.976 at the largest scale tested.
For a step by step walkthrough of deduplicating company and contact data, see How to Deduplicate a Contact List with Fuzzy Name Matching.
Cost and Accuracy Scaling
Everyone loves scaling laws, so we ran 5 more experiments featuring duplicates across different types of entities, and with different difficulty levels on how to tell if two rows actually matched.
| Dataset | Entity | Rows | Dup% | F1 | Precision | Recall | Cost | $/1k rows |
|---|---|---|---|---|---|---|---|---|
| Small Companies | company | 200 | 8% | 1.000 | 1.000 | 1.000 | $0.18 | $0.90 |
| Medium People | person | 1,000 | 20% | 0.994 | 0.993 | 0.996 | $1.18 | $1.18 |
| Medium Transactions | tsx | 1,000 | 20% | 0.945 | 0.928 | 0.963 | $1.41 | $1.41 |
| Large Companies (Messy) | company | 3,000 | 10% | 0.974 | 0.973 | 0.976 | $3.21 | $1.07 |
| Large Products (FDA like) | product | 5,000 | 5% | 0.997 | 0.998 | 0.996 | $6.37 | $1.27 |
All datasets use ground truth labels. F1 is the harmonic mean of Precision (how many merges were correct) and Recall (how many true duplicates were found). Cost is total LLM inference cost in USD.
The hardest dataset, Medium Transactions, involves property sale records where the same sale can appear with different address formats, and adjacent properties share parcel IDs. Even here, F1 reaches 0.945.
Understanding deduplication quality requires distinguishing two separate error types:
- Over merging (low Precision): Distinct entities are incorrectly grouped together. This causes data loss, you lose real records. This is the dangerous failure mode.
- Under merging (low Recall): True duplicates are missed. Your data stays messy, but nothing is lost. This is the safe failure mode.
EveryRow's dedupe tool is tuned to strongly prefer under merging over over merging. In the FDA dataset at 20,000 rows, Precision is 1.000 (zero false merges) while Recall is 0.992 (a small number of duplicates are missed). This means the system is conservative, it only merges when it is confident.
F1 score is the harmonic mean of Precision and Recall, summarizing overall quality in a single number. An F1 of 0.996 means the system is getting almost every decision right.
Steps to Reproduce
The FDA dataset can be found at FDA Drugs@FDA Data Files. Or you can deduplicate your own dataset:
-
Go to everyrow.io/app and sign in (should support about a 15k row dedupe on the free tier)
-
Upload your CSV and describe your equivalence relation, or add everyrow to Claude Code or Claude.ai and ask it there.
That's it.
from everyrow import create_client, create_session
from everyrow.ops import dedupe
import pandas as pd
input_df = pd.read_csv("your_data.csv")
async with create_client() as client:
async with create_session(client, name="Dedupe") as session:
result = await dedupe(
session=session,
input=input_df,
equivalence_relation=(
"Same company = same legal entity"
),
)
result.data.to_csv("deduplicated.csv", index=False)
Install with: pip install everyrow
Resources
- API reference
- everyrow.io/dedupe for the web UI and docs
- Entity Resolution on Wikipedia for background on the record linkage / entity resolution problem