Key Takeaways
- Widely cited reporting from The Information badly overestimated how big OpenAI's API business was in early 2024, claiming $1B ARR as of March when our figure of ~$500M was much more accurate given later disclosures
- Our ChatGPT Plus estimate of 7.7M subscribers was accurate, much more so than other public estimates at the time
- We overestimated ChatGPT Teams subscribers (900k estimate was way too high, likely ~100k actual)
From Estimates to Validation: Three Months Later
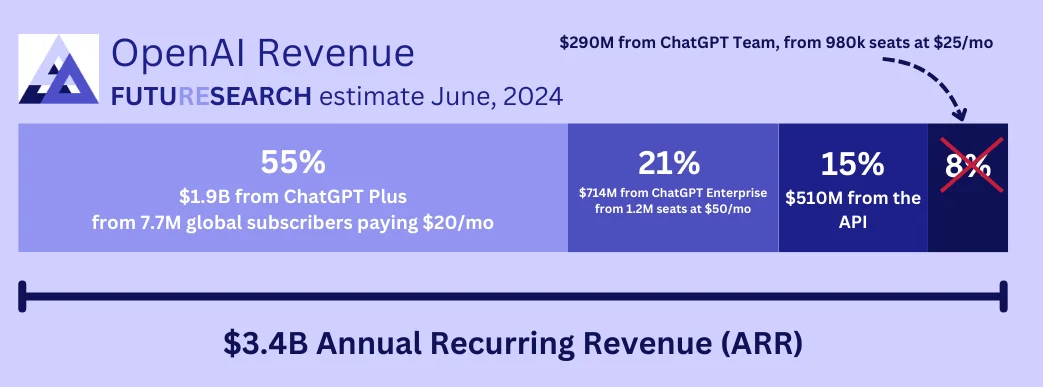
Shortly after reports of OpenAI's $3.4B ARR came out on June 12, FutureSearch released estimates on how much came from ChatGPT Plus/Teams/Enterprise, and the API, based on how many users.
Exactly 3 months later, on September 12, The Information reported a leak from OpenAI that an email from COO Brad Lightcap claimed more than 10M ChatGPT Plus subscribers, and 1M on "higher-priced plans."
Taking this leak at face value, what did we get right and wrong in our June numbers?
What We Got Right
ChatGPT Plus: 7.7M Subscribers Was Accurate
Our estimate of 7.7M ChatGPT Plus subscribers looked accurate, much more so than other estimates circulating at the time. The leaked information from OpenAI COO Brad Lightcap claiming "more than 10M" subscribers three months later aligns well with our June estimate, given the rapid (though slowing) growth we observed.
Our methodology involved analyzing data points, modeling growth trajectories, and inferring global subscriber numbers using reference classes like "viral consumer apps" and anchoring to plausible ancillary data.
API Revenue: ~$500M ARR Was On Target
Our API revenue estimate of ~$500M ARR looked accurate, validating our claim that it was significantly lower than was being reported in mainstream news.
We challenged widely reported numbers about API revenue by using a method of bounding growth and back-calculating revenue, while rejecting speculative numbers that didn't align with credible data sources.
What We Got Wrong
ChatGPT Teams: 900k Was Way Too High
Our estimate of 900k Teams subscribers was way too high. The actual number was likely much lower, around 100k.
This error stemmed from mistakes in our benchmarking and extrapolation methods. We neglected important "inside view" perspectives that would have suggested more conservative adoption rates for the Teams product.
ChatGPT Enterprise: 1.2M Was Possibly Too High
Our ChatGPT Enterprise estimate of 1.2M was possibly accurate, but probably too high. While we don't have definitive data on the actual Enterprise subscriber count, the overall pattern suggests our estimate was on the optimistic side.
The Value of Public Track Records
This case study highlights the importance of making public, falsifiable predictions and being transparent about methodology. By publishing our estimates in June and now evaluating them against September's leaked data, we demonstrate our commitment to accountability in forecasting.
We encourage you to treat claims on the internet like we do: trust them as much as their track records warrant.