Key Takeaways
- As later evidence shows (Deep Research Bench), while OpenAI's Deep Research tool was initially impressive, it actually underperformed the later release of ChatGPT-o3+search
- OpenAI Deep Research (OAIDR) shows a "jagged frontier" of performance—better than some competing systems but significantly worse than intelligent humans
- Overconfidence is a major issue: OAIDR often reports wrong answers confidently when it should admit uncertainty
- Peculiar source selection: The system frequently chooses company blogs or SEO-spam sites over authoritative sources
- Risk of misinformation by omission: Incomplete research that appears comprehensive is particularly dangerous
Mixed Reactions to OpenAI Deep Research
On February 3, OpenAI launched Deep Research, their long-form research tool, provoking a flurry of interest and intrigued reactions. Many were seriously impressed, while others warned of frequent inaccuracies.


FutureSearch conducted a detailed evaluation to understand OAIDR's true capabilities and limitations.
The Verdict: Better Than Some, Worse Than Humans
Our evaluation found that OAIDR is better than some competing systems but still significantly worse than human researchers. The system exhibits what researchers call a "jagged frontier" of performance—inconsistent quality that makes it difficult to predict when it will succeed or fail.
Key Failure Modes
- Overconfidence: Reports wrong answers when it should admit uncertainty
- Peculiar source selection: Prioritizes unreliable sources over authoritative ones
- Difficulty reading complex webpages: Struggles with PDFs, images, and certain website formats
- Misinformation by omission: Produces incomplete research that appears comprehensive
Recommended Usage
- Good for: Synthesizing information where completeness isn't critical
- Risky for: Topic introductions (high risk of missing key information)
- Potentially useful: Niche, qualitative explorations
Six Strange Failures: Detailed Examples
We tested OAIDR on six research queries where we knew the correct answers. Here's what we found:
Failure #1: Cybench Benchmark Performance
Query: Find the highest reported agent performance on the Cybench benchmark.
OAIDR's answer: 17.5% Correct answer: 34.5%
What went wrong: OAIDR failed to identify the top-performing model (o1) and reported an outdated figure. The system prioritized corroboration from multiple sources over finding the most recent and accurate data.

Failure #2: UK COVID Excess Deaths
Query: Determine the cumulative excess deaths per million in the UK by end of 2023.
OAIDR's answer: 2,730 Correct answer: 3,473
What went wrong: OAIDR used outdated data and extrapolated incorrectly, then sought corroboration from less reliable sources like Reddit instead of consulting the full Our World in Data dataset.

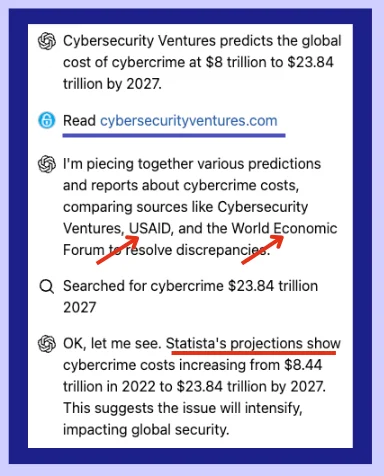
Failure #3: Cybercrime Cost Source Tracing
Query: Identify the original source of a widely-cited cybercrime cost projection.
OAIDR's answer: Attributed to Statista Correct answer: CyberSecurity Ventures
What went wrong: Despite finding the original CyberSecurity Ventures PDF, OAIDR incorrectly attributed the source to Statista. The system spent excessive time exploring multiple angles but failed to trace the source accurately.
Failure #4: Alternative Meat Market Size
Query: Find the global market size for alternative meat products in 2023.
OAIDR's answer: $7.2B from a low-quality source Correct answer: $6.4B from Good Food Institute
What went wrong: OAIDR reported finding and reading the authoritative Good Food Institute report but failed to extract the correct figure, instead relying on a less credible source.
Failure #5: Check Point Software Product Analysis
Query: Create a comprehensive table of Check Point Software products and their relationships to cyber attack types.
Result: OAIDR produced a table with only 34 of 45 possible products, with 118 out of 170 cells being correct.
What went wrong: The missing data was not obvious, demonstrating the challenge of detecting incomplete research. This "misinformation by omission" is particularly dangerous because the output appears comprehensive.
Failure #6: OpenAI's Current Projects
Query: Identify OpenAI's current research projects and initiatives.
What went wrong: OAIDR struggled to distinguish between confirmed projects and speculation, and missed several publicly announced initiatives due to peculiar source selection.
The Bottom Line: Use With Caution
OpenAI Deep Research represents progress in AI-powered research tools, but it's not ready to replace human researchers. The combination of overconfidence, unreliable source selection, and incomplete coverage creates significant risks for users who trust its outputs.
Our recommendation: Use OAIDR for preliminary exploration and information synthesis, but always verify critical facts with authoritative sources and human expertise.