LLM-Powered Data Labeling
Human data labeling is slow and expensive. LLM-powered labeling produces structured labels at scale, matching human annotator accuracy at a fraction of the cost.
Here, we label 200 text samples from the DBpedia-14 dataset into 14 ontology categories, achieving 98.5% accuracy.
| Metric | Value |
|---|---|
| Labels produced | 200 |
| Strict accuracy | 96.0% |
| Normalized accuracy | 98.5% |
| Time | 4.7 minutes |
| Cost | $3.35 |
Add FutureSearch to Claude Code if you haven't already:
claude mcp add futuresearch --scope project --transport http https://mcp.futuresearch.ai/mcp
Prepare a CSV with 200 text samples from the DBpedia-14 dataset. Tell Claude:
Classify each text in dbpedia_samples.csv into exactly one DBpedia ontology
category: Company, Educational Institution, Artist, Athlete, Office Holder,
Mean Of Transportation, Building, Natural Place, Village, Animal, Plant,
Album, Film, or Written Work.
Claude calls FutureSearch's agent MCP tool with the classification schema:
Tool: futuresearch_agent
├─ task: "Classify this text into exactly one DBpedia ontology category."
├─ input_csv: "/Users/you/dbpedia_samples.csv"
└─ response_schema: {"category": "enum of 14 DBpedia categories"}
→ Submitted: 200 rows for processing.
Session: https://futuresearch.ai/sessions/5f5a052a-c240-43d8-91a4-ad7ad274f6e1
Task ID: 5f5a...
Tool: futuresearch_progress
├─ task_id: "5f5a..."
→ Running: 0/200 complete, 200 running (15s elapsed)
...
Tool: futuresearch_progress
→ Completed: 200/200 (0 failed) in 279s.
Tool: futuresearch_results
├─ task_id: "5f5a..."
├─ output_path: "/Users/you/dbpedia_classified.csv"
→ Saved 200 rows to /Users/you/dbpedia_classified.csv
Add the FutureSearch connector if you haven't already. Then upload a CSV with 200 text samples from the DBpedia-14 dataset and ask Claude:
Classify each text into exactly one DBpedia ontology category: Company, Educational Institution, Artist, Athlete, Office Holder, Mean Of Transportation, Building, Natural Place, Village, Animal, Plant, Album, Film, or Written Work.
Go to futuresearch.ai/app, upload a CSV with 200 text samples from the DBpedia-14 dataset, and enter:
Classify each text into exactly one DBpedia ontology category: Company, Educational Institution, Artist, Athlete, Office Holder, Mean Of Transportation, Building, Natural Place, Village, Animal, Plant, Album, Film, or Written Work.
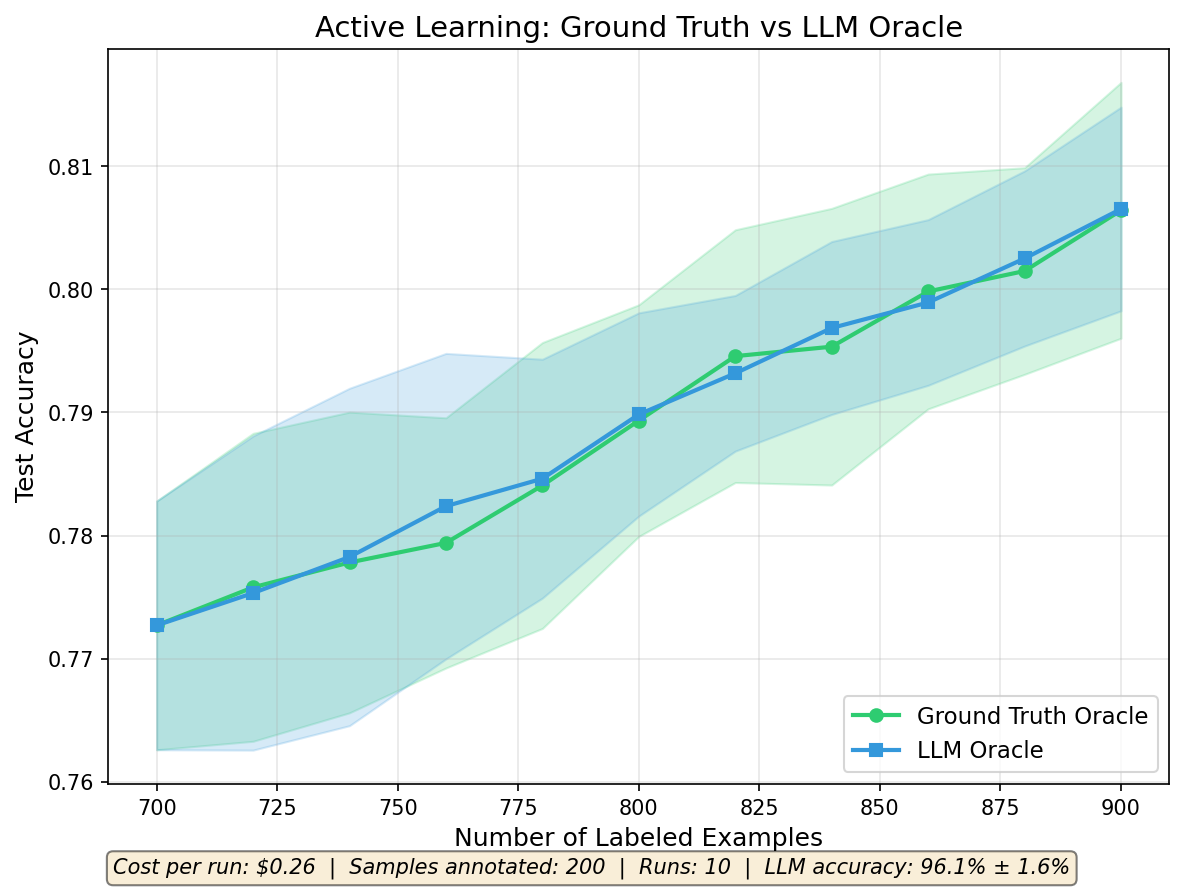
Using EffortLevel.LOW keeps the cost to $0.26 per run ($0.0013 per label). The learning curves between LLM and human annotation overlap almost perfectly.
pip install futuresearch
export FUTURESEARCH_API_KEY=your_key_here # Get one at futuresearch.ai/app/api-key
from typing import Literal
import pandas as pd
from pydantic import BaseModel, Field
from futuresearch import create_session
from futuresearch.ops import agent_map
from futuresearch.task import EffortLevel
LABEL_NAMES = {
0: "Company", 1: "Educational Institution", 2: "Artist",
3: "Athlete", 4: "Office Holder", 5: "Mean Of Transportation",
6: "Building", 7: "Natural Place", 8: "Village",
9: "Animal", 10: "Plant", 11: "Album", 12: "Film", 13: "Written Work",
}
CATEGORY_TO_ID = {v: k for k, v in LABEL_NAMES.items()}
class DBpediaClassification(BaseModel):
category: Literal[
"Company", "Educational Institution", "Artist",
"Athlete", "Office Holder", "Mean Of Transportation",
"Building", "Natural Place", "Village",
"Animal", "Plant", "Album", "Film", "Written Work",
] = Field(description="The DBpedia ontology category")
async def query_llm_oracle(texts_df: pd.DataFrame) -> list[int]:
async with create_session(name="Active Learning Oracle") as session:
result = await agent_map(
session=session,
task="Classify this text into exactly one DBpedia ontology category.",
input=texts_df[["text"]],
response_model=DBpediaClassification,
effort_level=EffortLevel.LOW,
)
return [CATEGORY_TO_ID.get(result.data["category"].iloc[i], -1)
for i in range(len(texts_df))]
The full pipeline is available as a companion notebook on Kaggle. See also the full blog post.
Results
| Category | Count |
|---|---|
| Building | 22 |
| Artist | 20 |
| Mean Of Transportation | 18 |
| Animal | 15 |
| Educational Institution | 15 |
| Company | 13 |
| Album | 13 |
| Office Holder | 12 |
| Film | 12 |
| Natural Place | 11 |
Of the 8 "strict" mismatches against ground truth, 5 were formatting variants (e.g., "WrittenWork" vs "Written Work"), not true errors. Only 3 were genuinely incorrect classifications: a Village labeled as Settlement, an Educational Institution labeled as University, and an Artist labeled as Writer. These are semantic near-misses, not random errors.
When used as an oracle in an active learning loop (10 iterations, 200 labels total, 10 independent repeats), the LLM oracle matches ground truth:
| Data Labeling Method | Final Accuracy (mean +/- std) |
|---|---|
| Human annotation (ground truth) | 80.6% +/- 1.0% |
| LLM annotation (FutureSearch) | 80.7% +/- 0.8% |
Built with FutureSearch. Related guides: Classify DataFrame Rows (label data at scale), Deduplicate Training Data (clean ML datasets before training).