Scale Deduplication to 20K Rows
Deduplication that scales linearly with dataset size. Embeddings and clustering narrow the search space first so LLM calls target ambiguous pairs instead of all 200 million possible combinations. Here, 20,000 FDA drug product records are deduplicated using a funnel of embeddings, clustering, and targeted LLM calls.
| Metric | Value |
|---|---|
| Input rows | 20,000 |
| Unique after dedupe | 18,078 |
| Duplicates removed | 1,922 (9.6%) |
| Time | ~22 minutes |
| Cost | ~$22-26 |
Go to futuresearch.ai/app, upload fda_products.csv, and enter:
Deduplicate this dataset. Two rows are duplicates if they have the same ingredient + same strength + same applicant + same dosage form.
20,000 rows deduplicated in about 22 minutes. 1,922 duplicates removed (9.6% reduction).
Add the FutureSearch connector if you haven't already. Then upload fda_products.csv and ask Claude:
Deduplicate this dataset. Two rows are duplicates if they have the same ingredient + same strength + same applicant + same dosage form.
20,000 rows deduplicated in about 22 minutes. 1,922 duplicates removed (9.6% reduction).
Add FutureSearch to Claude Code if you haven't already:
claude mcp add futuresearch --scope project --transport http https://mcp.futuresearch.ai/mcp
Download fda_products.csv (20,000 rows from the FDA Drugs@FDA database with ingredient, strength, applicant, and dosage form columns). Tell Claude:
Deduplicate fda_products.csv. Two rows are duplicates if they have the same
ingredient + same strength + same applicant + same dosage form.
Claude calls FutureSearch's dedupe MCP tool:
Tool: futuresearch_dedupe
├─ equivalence_relation: "Same ingredient + same strength + same applicant + same dosage form = duplicate"
└─ input_csv: "/Users/you/fda_products.csv"
→ Submitted: 20,000 rows for deduplication.
Session: https://futuresearch.ai/sessions/71e68a7f-a856-43ba-8080-89e4093afb1c
Task ID: 71e6...
Tool: futuresearch_progress
├─ task_id: "71e6..."
→ Running: 0/20000 complete (60s elapsed)
...
Tool: futuresearch_progress
→ Completed: 20000/20000 (0 failed) in 1350s.
Tool: futuresearch_results
├─ task_id: "71e6..."
├─ output_path: "/Users/you/fda_deduplicated.csv"
→ Saved 20000 rows to /Users/you/fda_deduplicated.csv
20,000 rows deduplicated in 22.5 minutes for $26.11 ($1.31 per 1,000 rows). View the session.
pip install futuresearch
export FUTURESEARCH_API_KEY=your_key_here # Get one at futuresearch.ai/app/api-key
import asyncio
import pandas as pd
from futuresearch.ops import dedupe
data = pd.read_csv("fda_products.csv")
async def main():
result = await dedupe(
input=data,
equivalence_relation=(
"Same ingredient + same strength + same applicant "
"+ same dosage form = duplicate"
),
)
clean = result.data[result.data["selected"] == True]
print(f"Reduced {len(data)} to {len(clean)} unique records")
clean.to_csv("deduplicated.csv", index=False)
asyncio.run(main())
Results
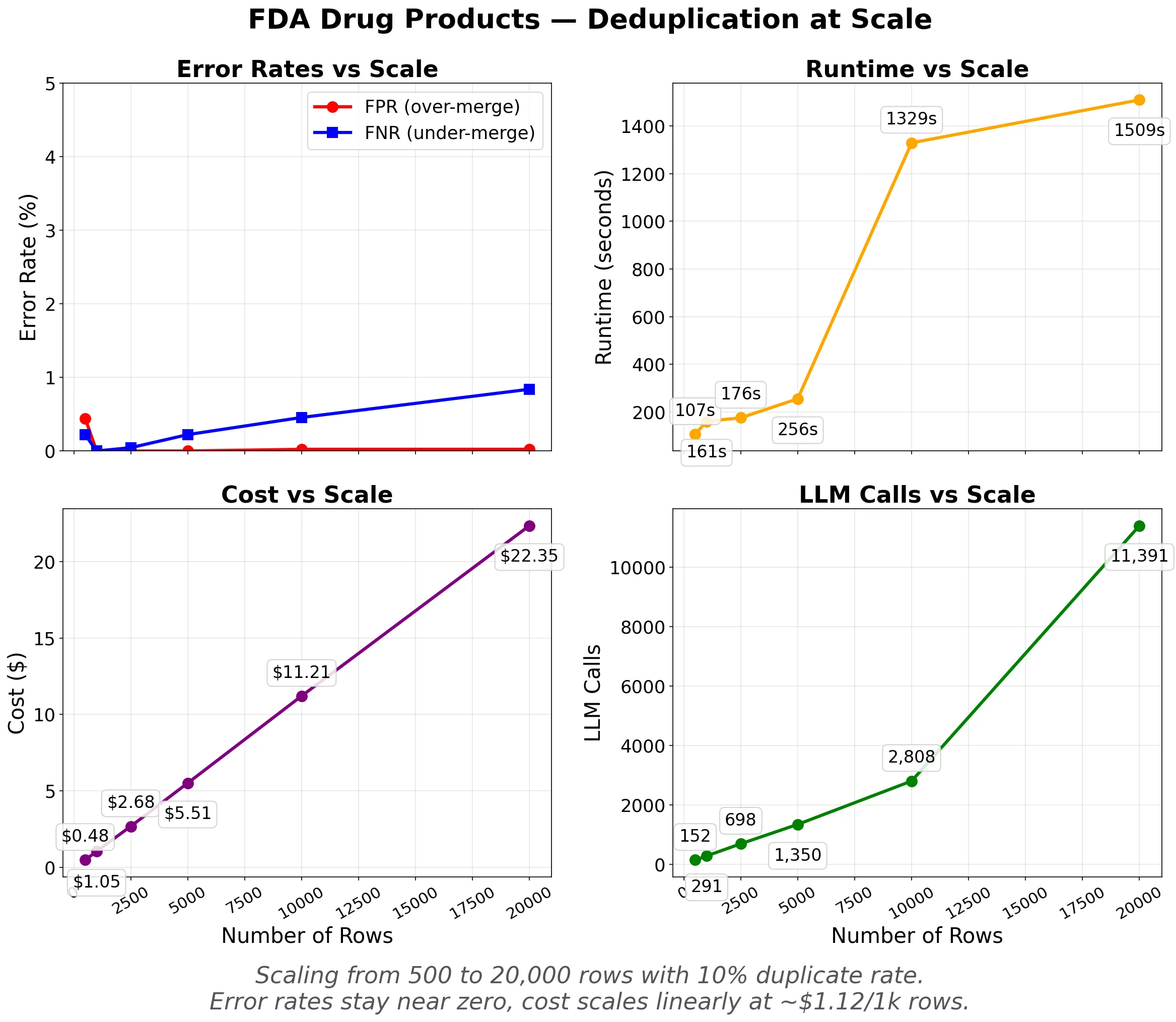
Error rates stay near zero as scale increases. Cost and LLM calls scale linearly. Runtime is under 5 minutes up to 10,000 rows and 25 minutes at 20,000.
| Cluster | Members | Pattern |
|---|---|---|
| Oxytocin / Fresenius Kabi | 3 | Different package sizes: 10/100/300 USP units, same concentration |
| Gadodiamide / GE Healthcare | 3 | Different volumes: 287mg/mL in bulk vs 50mL vs 100mL |
| Diazepam / Hikma | 3 | Strength formatting: "50MG/10ML (5MG/ML)" vs "5MG/ML" |
| Acyclovir 800MG / Teva | 3 | Company variants: TEVA, IVAX SUB TEVA PHARMS, TEVA PHARMS |
The pipeline catches semantic duplicates across strength formatting variants, company name variations, and minor formatting differences.
Cost Scaling
Cost stays between $0.90 and $1.50 per 1,000 rows across all datasets tested:
| Dataset | Entity | Rows | Dup% | F1 | Cost | $/1k rows |
|---|---|---|---|---|---|---|
| Small Companies | company | 200 | 8% | 1.000 | $0.18 | $0.90 |
| Medium People | person | 1,000 | 20% | 0.994 | $1.18 | $1.18 |
| Medium Transactions | transaction | 1,000 | 20% | 0.945 | $1.41 | $1.41 |
| Large Companies (Messy) | company | 3,000 | 10% | 0.974 | $3.21 | $1.07 |
| Large Products (FDA) | product | 5,000 | 5% | 0.997 | $6.37 | $1.27 |
| Company Names | company | 8,628 | 10% | 0.976 | $12.58 | $1.46 |
| FDA Products | product | 20,000 | 10% | 0.996 | $22.40 | $1.12 |
Rough formula: $1-1.50 per 1,000 rows depending on data complexity.
Precision and Recall
Every deduplication system makes two kinds of mistakes. Over-merging (low Precision) is data loss: distinct entities incorrectly grouped together. Under-merging (low Recall) means your data stays messy, but nothing is lost. At 20,000 rows, Precision is 1.000 (zero false merges) while Recall is 0.992 (8 of ~2,000 duplicates were missed). The system only merges when it's confident.
The equivalence_relation parameter is the single most important input. Be specific and enumerate the fields that must match:
# Good: mentions all matching fields
equivalence_relation="Same ingredient + same strength + same applicant + same dosage form = duplicate"
# Less good: vague
equivalence_relation="Same drug"
Built with FutureSearch. See the dedupe documentation for more options. Related guides: Resolve Duplicate Entities (500-row CRM walkthrough), Deduplicate Training Data (semantic dedup for ML datasets).